LCS는 두가지의 의미가 있습니다.
기본적으론 최장 공통 부분수열(Longest Common Subsequence)이고, 최장 공통 문자열(Longest Common Substring)을 의미하기도 합니다.

위의 예시처럼 최장 공통 부분수열(Longest Common Subsequence)인 왼쪽은 문자 사이가 다른 글자여도 공통된 문자열을 찾습니다.(부분수열이므로)
반면에, 최장 공통 문자열(Longest Common Substring)인 오른쪽은 연속으로 이어진 문자열에 대해서만 찾습니다.
최장 공통 부분수열(Longest Common Subsequence)
대게 이러한 형식의 문제는 2차원 배열을 만들어서 계산된 값을 참조하여 값을 증가시키거나 유지합니다.
https://www.acmicpc.net/problem/9251
백준 9251번 LCS 대표문제를 보며 어떤 형식으로 풀어야되는지 알아보겠습니다.
문제의 이론은 머리로 이해하기엔 어렵지 않습니다. 두 값의 중복되는 문자들 중 가장 긴 수를 추출하면됩니다. 이러한 값들을 계산하기위해 일일이 계산하는 것은 시간 초과나 메모리 초과를 초래하게 됩니다.
해결을 위해선 DP를 사용해야하고 Base의 값들을 재참조하여 다음값을 구하면됩니다. 이 과정을 위해 2차원 배열을 쓰는 것입니다.
그럼 점화식은 어떻게 유추할까요? 점화식을 찾기 쉽지 않습니다.
문자열을 비교해서 같다면, 해당되는 배열의 값에 +1을 해줍니다. 만약, 같지 않다면, 전에 비교한 값중 큰 값을 참조하여 불러옵니다. 이걸 파이썬으로 나타내면 다음과 같습니다.
import sys
input = sys.stdin.readline
A = input().strip()
n = len(A) # 6
B = input().strip()
m = len(B) # 6
dp = [[0] * (m + 1) for _ in range(n + 1)] # 7 * 7
for i in range(1, n + 1):
for j in range(1, m + 1):
if A[i - 1] == B[j - 1]: # 값이 같다면
dp[i][j] = dp[i-1][j-1] + 1
else: # 값이 다르다면
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
print(dp[n][m])코드를 보면 이상한게 있습니다. 왜 필요도 없는 0 마진을 두는가, n을 +1 했다가 나중에 다시 -1을 하는 이유가 무엇인가…
배열을 직접 그려보면 아시겠지만, 0마진이 없으면 비교가 되지않아 연산 오류가 생깁니다. 그리고 계산을 위해 인덱스가 1부터 시작하는데, 이걸 변환하는 과정에서 +1과 -1을 하게됩니다.
점화식은 if문이며 두 문자가 같으면 dp[i - 1][j - 1] + 1 을 해주고, 다르다면 dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) 을 하여 전에 있는 값 중 최대를 가져옵니다.
[구현과정]
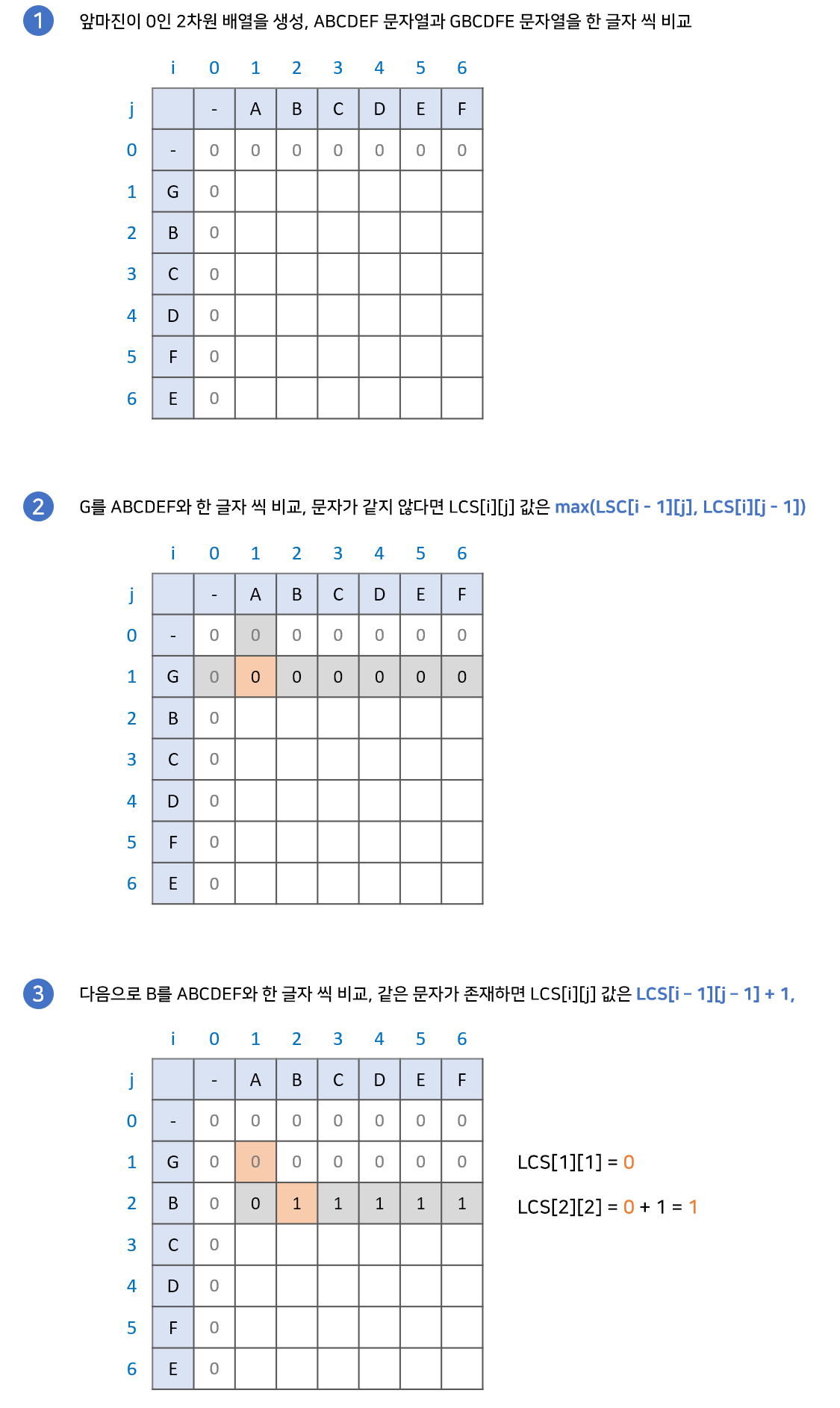
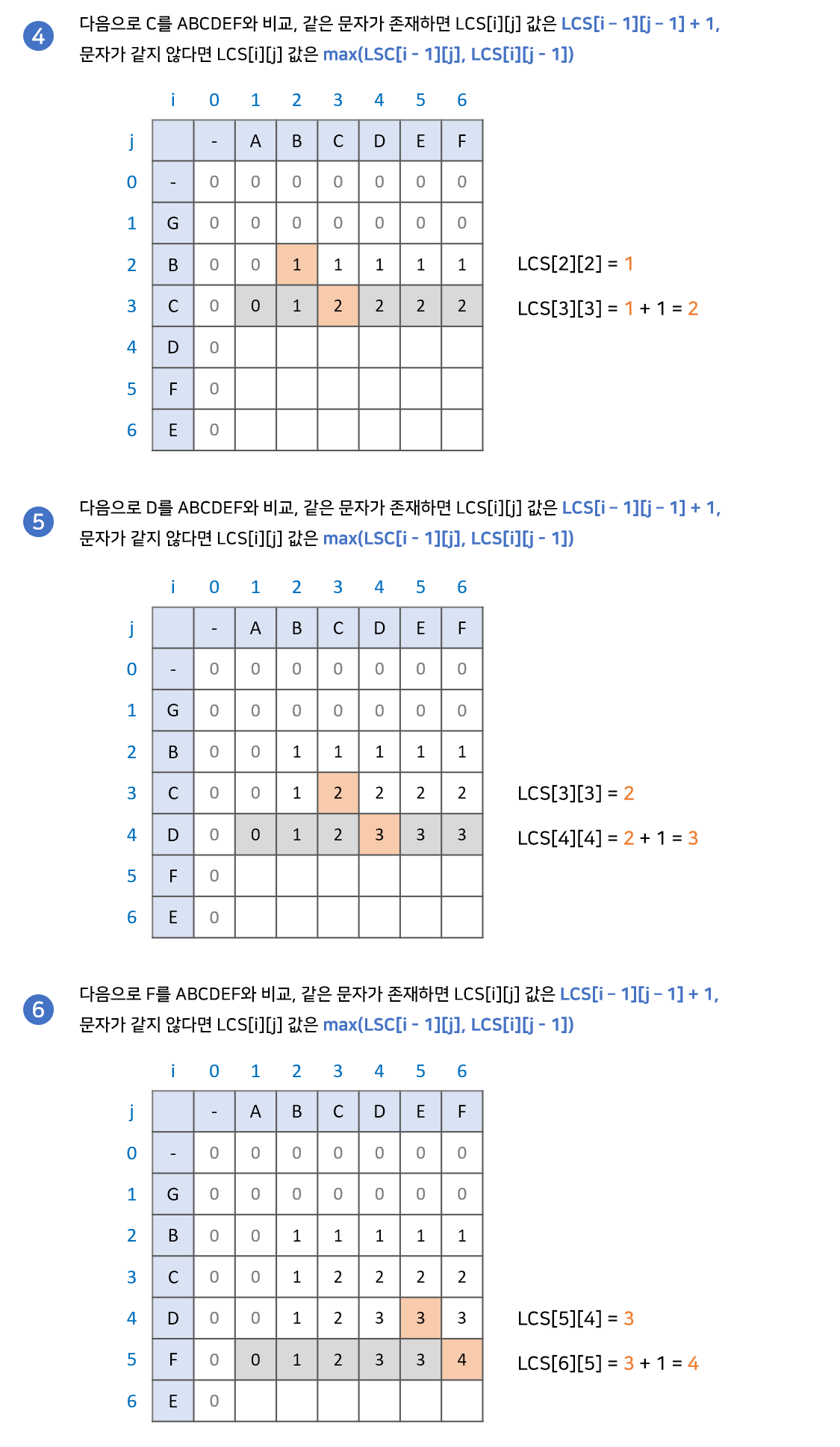

이와 같은 과정으로 최종답안인 4를 결과로 반환하게 됩니다.
문자가 같으면, dp[i - 1][j - 1] + 1 을 하는 이유는 위의 배열에서 ABC와 GBC의 최장 공통 부분 수열은 AB와 GB의 최장 공통 부분 수열 +1과 같기 때문입니다.
문자가 다르면, dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) 을 하는 이유는 문자를 비교하는 그 전 값을 가져오기 위함입니다. 위의 배열에서 AB와 GBC의 최장 공통 부분수열은 A와 GBC의 최장 공통 부분수열(현재 줄) 또는 AB와 GB의 최장 공통 부분수열(이전 줄) 중 최댓값이기 때문입니다.
+최장 공통 부분 수열에 해당되는 문자열을 출력하는 방법도 있는데, 그 방법은 위의 벨로그 마지막 부분을 참고하시면 될 것 같습니다.
최장 공통 문자열(Longest Common Substring)
위의 개념을 이해하셨다면, 공통 문자열을 구하는건 한결 쉽습니다.
문자열이 연속되어야되므로 같은 수를 연속으로 찾았을때 +1만 해주고 나머지칸은 0으로 처리하면 됩니다. 만약에 중간에 중복되지 않는다면, 1부터 다시 세야합니다.
코드는 다음과 같습니다. 밑에 있는 배열을 보면 한결 이해하기 쉬울 것 입니다.
import sys
input = sys.stdin.readline
A = input().strip()
B = input().strip()
n = len(A)
m = len(B)
# dp[i][j]는 A[i-1]와 B[j-1]에서 끝나는 공통 문자열의 길이
dp = [[0] * (m + 1) for _ in range(n + 1)]
max_length = 0 # 최장 공통 문자열의 길이 저장
for i in range(1, n + 1):
for j in range(1, m + 1):
if A[i - 1] == B[j - 1]:
# 연속되는 문자열이므로 이전 dp[i-1][j-1]에 1 추가
dp[i][j] = dp[i - 1][j - 1] + 1
max_length = max(max_length, dp[i][j]) # 최댓값 갱신
else:
dp[i][j] = 0 # 연속되지 않으면 끊김
print(max_length)
[구현과정]

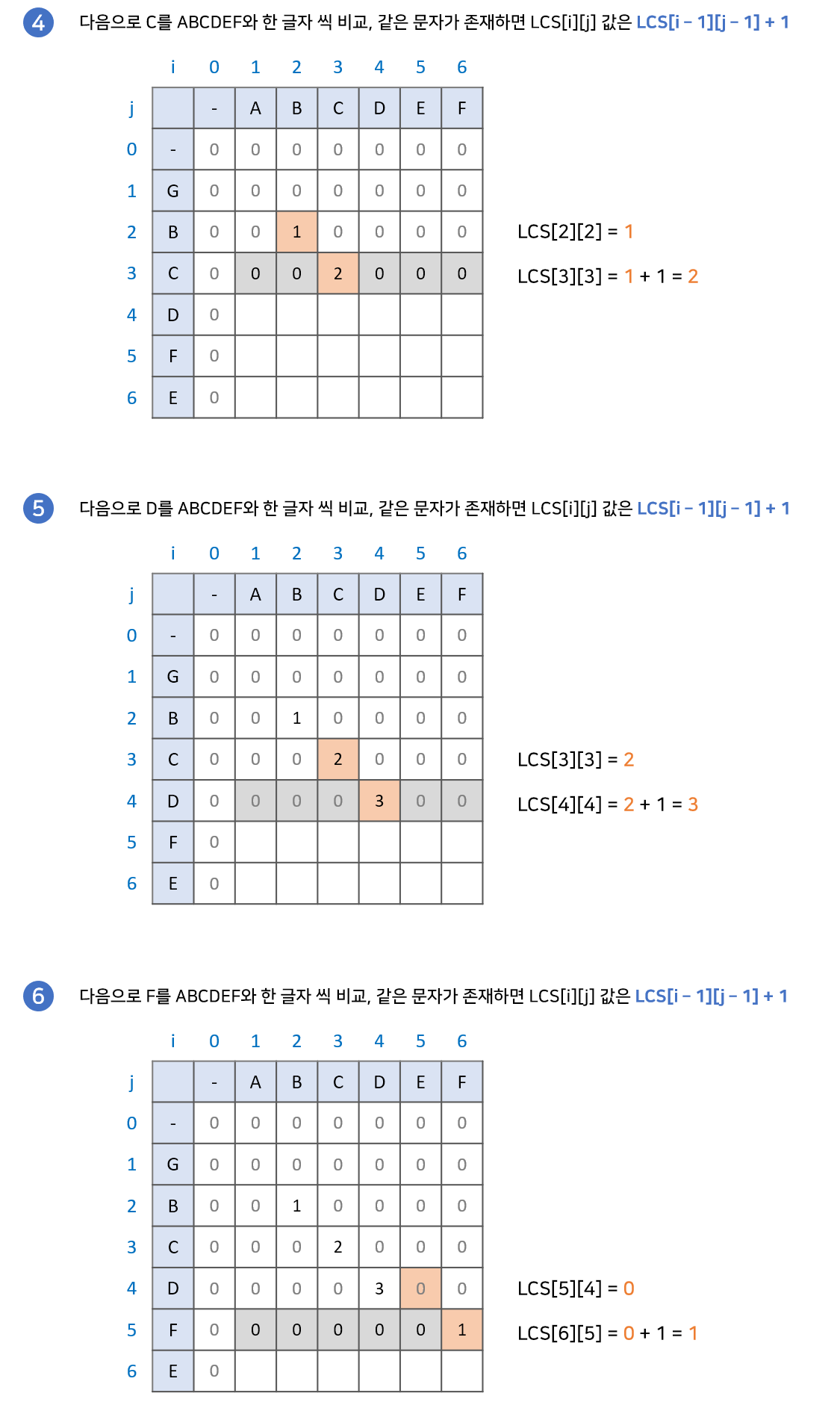
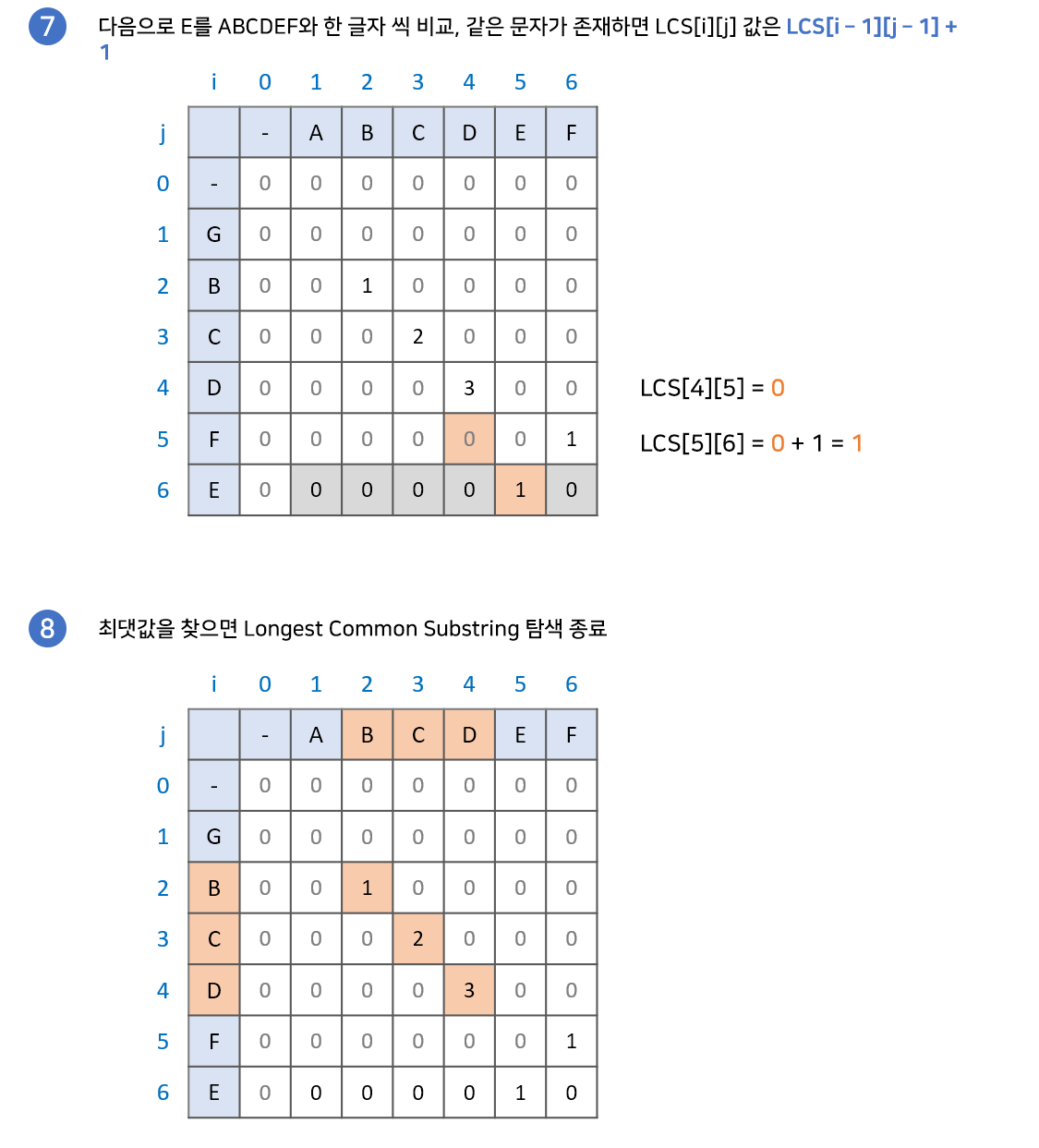
끝까지 구한다음 저장된 배열 중 가장 큰 max값을 출력하면 됩니다.
'크래프톤 정글(알고리즘 주차 WEEK 0 ~ 4)' 카테고리의 다른 글
| WEEK 04 여담(4월6일 일요일) (0) | 2025.04.11 |
|---|---|
| WEEK 04 알고리즘 TIL(4월5일 토요일) (0) | 2025.04.11 |
| WEEK 04 알고리즘 TIL(4월4일 금요일) (0) | 2025.04.11 |
| DP(동적 프로그래밍) (0) | 2025.04.11 |
| WEEK 03 알고리즘 TIL(4월3일 목요일) (0) | 2025.04.03 |