Proxy 서버 C언어 구현
해당 포스팅은 Proxy 서버 C언어 구현에 대한 분석 내용을 설명합니다. 앞의 포스팅을 통해 Proxy의 개념과 특성을 알고 넘어오시길 추천드립니다.
글의 흐름(티스토리는 인덱스를 지원안하네요...)
프록시 서버 요구사항 → 함수별 설명 → proxy.c 전체 코드 → 코드 테스트 방법 → 전체 내용 요약
Proxy 서버 코드 분석
클라이언트(사용자)와 인터넷 사이에 위치한 중계 서버입니다. 사용자가 웹사이트에 직접 접속하지 않고, 프록시 서버를 통해 접속하게 함으로써 다양한 기능과 이점을 제공합니다.
앞으로 우리는 Proxy의 역할을 고려하여 코드를 작성할 것입니다.
우리가 구현할 프록시 서버는 클라이언트의 HTTP 요청을 받아 서버에 전달하고, 서버의 응답을 다시 클라이언트에게 반환합니다. 응답을 빠르게 하기위한 캐시 기능도 포함하고 있습니다.
Proxy 서버 요구사항
https://e-juhee.tistory.com/entry/C%EC%96%B8%EC%96%B4-Proxy-Lab-Proxy-Server-%EA%B5%AC%ED%98%84%ED%95%98%EA%B8%B0-Sequential-proxy-Concurrent-proxy-Caching
해당 블로그를 참고하여 작성하였습니다.
- 순차적 웹 프록시 구현하기
들어오는 연결을 수락하고, 요청을 읽고 구문을 분석해야합니다. 웹 서버에는 요청을 전달하고 서버의 응답을 읽고 지정된 클라이언트에게 응답을 전달해야합니다. - 여러 동시 요청 처리
다중 동시 연결을 처리할 수 있는 프록시로 기능을 추가해야합니다.
CSAPP 12장의 동시성 처리/스레드에 대한 지식이 있어야합니다. - 웹 콘텐츠에 대한 캐싱 (최근)
최근 액세스한 웹 콘텐츠의 간단한 메인 메모리 캐시를 사용하여 프록시에 캐싱을 추가해야합니다. - 고득점을 위한 추가 요구사항 충족
추가 요구사항
- 소켓 입력 및 출력을 위해 표준 I/O 함수를 사용하는 것은 문제가 될 수 있으므로 Robust I/O(RIO) 패키지를 사용한다. (csapp.c에 내장되어 있다.)
- 모듈화 등을 고려하여 모든 파일을 수정할 수 있다.예를 들어 cache 기능을 구현할 때에는 모듈성을 고려하여 cache.c 및 cache.h 파일과 같은 라이브러리를 만들 수 있으며, 그럴 경우 Makefile도 수정해야 한다.
- 프록시 서버는 SIGPIPE(닫힌 소켓에 데이터 보냈을때 발생) 시그널을 무시해야 한다. (928p 참고)
- 웹에서 전송되는 모든 콘텐츠가 ASCII 텍스트가 아니다.네트워크 I/O와 바이너리 데이터(ex: 이미지, 동영상 등의 이진 데이터)를 다룰 때는 이진 데이터를 처리하기 위한 적절한 함수를 사용해야 한다.
- 원래 요청이 HTTP/1.1인 경우에도 모든 요청은 HTTP/1.0으로 전달되어야 한다.
proxy.c
함수 선언부
프록시 서버의 구조와 캐시 구현의 기본 틀을 보여줍니다. 이후의 구현에서는 실제 요청을 처리하고, 캐시를 확인하고, 엔드서버에 요청을 전달하며, 응답을 다시 클라이언트에게 전달하는 로직이 작성됩니다.
#include <stdio.h>
#include "csapp.h" // csapp 라이브러리는 CS:APP 교재에서 제공하는 네트워크 및 시스템 프로그래밍 지원 함수 모음입니다.
/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000 // 캐시 전체 최대 크기 (약 1MB)
#define MAX_OBJECT_SIZE 102400 // 한 객체의 최대 크기 (약 100KB)
/* You won't lose style points for including this long line in your code */
// 프록시 서버가 요청할 때 사용하는 User-Agent 헤더
static const char *user_agent_hdr =
"User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 "
"Firefox/10.0.3\r\n";
// 연결을 닫도록 지정하는 HTTP 헤더
static const char *conn_hdr = "Connection: close\r\n";
static const char *prox_hdr = "Proxy-Connection: close\r\n";
// Host 헤더를 만들기 위한 형식 문자열
static const char *host_hdr_format = "Host: %s\r\n";
// GET 요청을 위한 형식 문자열
static const char *requestlint_hdr_format = "GET %s HTTP/1.0\r\n";
// HTTP 요청 헤더의 끝을 나타낸다.
static const char *endof_hdr = "\r\n";
// 특정 헤더 이름을 비교할 때 사용하기 위한 문자열 상수
static const char *connection_key = "Connection";
static const char *user_agent_key= "User-Agent";
static const char *proxy_connection_key = "Proxy-Connection";
static const char *host_key = "Host";
// 클라이언트 요청을 처리하는 함수
void doit(int connfd);
// URI를 호스트명, 경로(path), 포트로 분해하는 함수
void parse_uri(char *uri,char *hostname,char *path,int *port);
// 클라이언트의 요청을 바탕으로 서버에 보낼 HTTP 헤더를 작성하는 함수
void build_http_header(char *http_header,char *hostname,char *path,int port, rio_t *client_rio);
// 엔드서버와 연결하는 함수
int connect_endServer(char *hostname,int port,char *http_header);
// 멀티스레딩 처리를 위한 함수
void *thread(void *vargsp);
// functions for caching
void init_cache(void); // 캐시 초기화
int reader(int connfd, char *url); // 클라이언트가 요청한 URL이 캐시에 존재하는지 확인하고 데이터를 전송하는 함수 (리더 역할)
void writer(char *url, char *buf); // 새 데이터를 캐시에 저장하는 함수 (라이터 역할)
// 개별 캐시 블록 정보를 담을 구조체
typedef struct {
char *url; // 요청된 URL
int *flag; // 캐시 블록이 사용 중인지 아닌지 표시 (0: 빈 블록, 1: 사용 중)
int *cnt; // 사용 빈도 또는 LRU 정책을 위한 카운트
int *content; // 실제 응답 데이터를 저장하는 공간 (클라이언트에 보낼 내용)
} Cache_info;
Cache_info *cache; // 캐시 전체를 담을 포인터 배열
int readcnt; // 동시에 읽는 reader 수를 관리하기 위한 변수
sem_t mutex, w; // 세마포어: mutex는 reader 수 갱신, w는 writer 접근 제어용main 함수
main 함수는 프록시 서버의 초기 설정을 담당하는 진입점(entry point) 역할을 합니다.
초기화 → 연결 대기 → 요청 처리의 전체 흐름을 설정하고, 멀티스레딩으로 동시성 처리를 가능하게 하여 실제 서비스 환경에 적합한 구조를 갖추게 합니다.
역할
- 입력 인자 확인 및 초기화
- 캐시 초기화
- 서버 소켓 생성 및 바인딩
- 클라이언트 연결 무한 루프 처리, 요청 수락, 정보 출력
- 스레드를 이용한 병렬 처리
int main(int argc, char **argv) {
// 포트 번호가 입력되지 않았을 시, 사용법 출력
if(argc != 2) {
fprintf(stderr, "usage :%s <port> \n", argv[0]);
exit(1);
}
init_cache(); // 캐시 초기화 함수 호출
int listenfd, connfd;
socklen_t clientlen;
char hostname[MAXLINE], port[MAXLINE];
struct sockaddr_storage clientaddr;
pthread_t tid;
listenfd = Open_listenfd(argv[1]); //클라이언트로부터 연결을 수신할 소켓을 열고 대기 상태로 만든다.
// 무한 루프: 클라이언트의 연결 요청을 지속적으로 수락
while(1) {
clientlen = sizeof(clientaddr);
// 클라이언트의 연결 요청을 수락하고, 연결된 소켓의 파일 디스크립터 변환
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
// 연결된 클라이언트의 호스트명과 포트 정보를 가져온다
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s %s).\n",hostname, port);
// 새로운 스레드를 생성하여 클라이언트 요청을 처리 (connfd를 인자로 전달)
Pthread_create(&tid, NULL, thread, (void *)connfd);
}
return 0;
}thread 함수
thread 함수는 클라이언트와 연결된 소켓을 받아서, 해당 요청을 처리(doit)하고, 작업이 끝나면 소켓을 닫아주는 스레드 작업 루틴입니다.
병렬성과 자원 효율성을 모두 고려한 구조로, 웹 서버와 프록시 서버에 흔히 사용됩니다.
void *thread(void *vargs) {
int connfd = (int)vargs; // main 함수에서 전달받은 연결 소켓 번호를 정수형으로 변환
Pthread_detach(pthread_self()); // 현재 스레드를 분리 상태로 설정하고, 스레드 종료시 자동으로 자원이 반환되어 메모리 누수 방지함
doit(connfd); // 클라이언트 요청 처리 (HTTP 요청을 파싱하고 응답 생성 등 역할)
Close(connfd); // 처리 후 클라이언트 소켓 닫음
}doit 함수
doit 함수는 프록시 서버에서 가장 핵심적인 역할을 담당하는 함수입니다. 프록시 서버가 해야할 모든 일이 해당 함수에 포함됩니다.
역할
- 클라이언트 요청 파싱
- 엔드 서버와의 통신 중계
- 응답 데이터 전달
- 캐싱 처리
처리 흐름
- 클라이언트 요청을 읽고, HTTP 메서드와 URI, 버전 추출
- GET 요청인지 확인 (다른 메서드는 처리 X)
- 캐시에 해당 URL 응답이 있는지 확인하고 있으면 반환
- URI을 파싱해 엔드 서버의 hostname, path, port 추출
- 엔드 서버로 보낼 HTTP 요청 헤더 생성
- 엔드 서버 연결
- 엔드 서버에 생성한 HTTP 요청을 전송
- 엔드 서버로부터 받은 응답을 클라이언트로 전송
- 응답을 캐시에 저장 (최대 크기 제한 내에서)
- 엔드 서버와의 연결 종료
void doit(int connfd) {
int end_serverfd; // 엔드서버(tiny.c)와 연결된 파일 디스크립터
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE]; // 요청 라인을 저장할 변수들
char endserver_http_header[MAXLINE]; // 엔드서버에 보낼 최종 HTTP 헤더
// URI 파싱을 통해 추출할 값들
char hostname[MAXLINE], path[MAXLINE];
int port;
rio_t rio, server_rio; // 클라이언트와 통신할 rio / 엔드서버와 통신할 rio 선언
char url[MAXLINE]; // 요청받은 URL 저장용
char content_buf[MAX_OBJECT_SIZE]; // 캐시에 저장할 응답 데이터 버퍼
// 1. 클라이언트 요청 라인 읽기: ex) GET http://localhost:8000/home.html HTTP/1.1
Rio_readinitb(&rio, connfd); // 클라이언트 소켓에 대해 rio 초기화
Rio_readlineb(&rio, buf, MAXLINE); // 요청 라인 한 줄 읽기
sscanf(buf, "%s %s %s", method, uri, version); // (메서드, URI, 버전) 파싱
strcpy(url, uri); // 캐시 키로 사용할 URL 복사
// 2. GET 요청만 지원함 (다른 메서드 무시)
if (strcasecmp(method, "GET")) { // method가 GET으로 같으면 0(false)를 반환함 즉, 다르다면 출력함
printf("Proxy does not implement the method"); // 에러 출력
return;
}
// 3. 캐시에 해당 요청 결과가 있는지 확인 (있으면 클라이언트에 바로 응답 후 종료)
if (reader(connfd, url)) {
return ;
}
// 4. URI를 파싱하여 hostname(localhost), path, port(20000) 추출
// 프록시 서버가 엔드 서버로 보낼 정보들을 파싱
parse_uri(uri, hostname, path, &port);
// 5. 엔드서버에 보낼 요청 헤더 구성 (GET /path HTTP/1.0 + Host + User-Agent 등)
// 프록시 서버가 엔드 서버로 보낼 요청 헤더들을 만든다. endserver_http_header가 채워짐
build_http_header(endserver_http_header, hostname, path, port, &rio);
// 6. 엔드서버에 연결 시도
// 프록시 서버와 엔드 서버를 연결함
end_serverfd = connect_endServer(hostname, port, endserver_http_header); // 프록시 측에서 엔드 서버로 연결된 clinetfd
if (end_serverfd < 0) {
printf("connection failed\n"); // 연결 실패시 종료
return;
}
// 7. 엔드서버에 HTTP 요청 헤더 전송
Rio_readinitb(&server_rio, end_serverfd); // 엔드서버와 소켓에 대해 rio 초기화
Rio_writen(end_serverfd, endserver_http_header, strlen(endserver_http_header)); // HTTP 요청 헤더 전송
// 8. 엔드서버의 응답 메시지를 읽어서 클라이언트에 보내고, content_buf에 복사
size_t n;
int total_size = 0; // content_buf에 저장한 총 크기 (캐시용)
while((n = Rio_readlineb(&server_rio,buf, MAXLINE)) != 0) {
printf("proxy received %d bytes,then send\n",n); // 디버깅 로그
Rio_writen(connfd, buf, n); // 클라이언트에 응답 전달
// connfd -> client와 proxy 연결 소켓. proxy 관점.
// 캐시 버퍼에 응답 내용 저장 (최대 크기 초과하지 않도록)
if (total_size + n < MAX_OBJECT_SIZE) {
strcpy(content_buf + total_size, buf);
}
total_size += n;
}
// 9. 전체 응답 크기가 MAX_OBJECT_SIZ 보다 작으면 캐시에 저장
if (total_size < MAX_OBJECT_SIZE) {
writer(url, content_buf);
}
// 10. 엔드서버와 연결 종료
Close(end_serverfd);
}| 단계 | 설명 |
|---|---|
| 요청 수신 | 클라이언트의 HTTP 요청을 읽는다. |
| 메서드 확인 | GET 요청만 처리 가능 (다른 것은 무시). |
| 캐시 확인 | 요청한 URL의 응답이 캐시에 있으면 바로 반환. |
| URI 파싱 | hostname, path, port로 나눈다. |
| 요청 헤더 구성 | 엔드서버에 보낼 헤더 작성. |
| 서버 연결 | 엔드서버에 연결 요청. |
| 요청 전달 | 엔드서버에 HTTP 요청 전송. |
| 응답 수신 | 엔드서버의 응답을 읽고 클라이언트에 전달. |
| 캐시 저장 | 응답 전체가 작으면 캐시에 저장. |
| 자원 정리 | 엔드서버 연결 종료. |
build_http_header 함수
build_http_header 함수는 프록시 서버가 엔드 서버에 전달할 HTTP 요청 헤더를 생성하는 함수입니다.
클라이언트가 보낸 원래 요청에서 불필요한 헤더를 제거하고, 필요한 헤더를 추가하여 정제된 HTTP 요청 헤더를 만듭니다.
- 클라이언트의 요청은 HTTP/1.1일 수 있지만, 프록시는 HTTP/1.0 형식으로 엔드 서버에 요청을 보냅니다.
- 클라이언트가 보내는 헤더 중 일부는 프록시가 직접 관리해야 하기 때문에 제거하거나 수정해야 합니다.
예:Connection,Proxy-Connection등은 프록시가 연결을 관리하므로 무시하고 새로 작성. - 이를 통해 정상적이고 호환성 있는 요청을 보장하고, 불필요한 헤더로 인한 오류를 방지합니다.
처리 흐름
GET /경로 HTTP/1.0형태의 요청 라인을 작성- 클라이언트가 보낸 요청 헤더에서
Host, 기타 헤더들 추출 Connection,Proxy-Connection,User-Agent는 프록시에서 고정값 사용- Host 헤더가 없으면 hostname으로 직접 생성
- 위 정보들을 조합해 최종 HTTP 헤더 문자열을 만듦
void build_http_header(char *http_header,char *hostname,char *path,int port,rio_t *client_rio) {
char buf[MAXLINE],request_hdr[MAXLINE],other_hdr[MAXLINE],host_hdr[MAXLINE];
/* 요청 헤더 초기화 */
memset(buf, 0, MAXLINE);
memset(request_hdr, 0, MAXLINE);
memset(other_hdr, 0, MAXLINE);
memset(host_hdr, 0, MAXLINE);
// 1. 요청 라인 작성: ex) GET /index.html HTTP/1.0
sprintf(request_hdr, requestlint_hdr_format, path);
// 2. 클라이언트 요청 헤더 읽으면서 필요한 부분만 필터링
// 클라이언트 요청 헤더들에서 Host header와 나머지 header들을 구분해서 넣어줌
while(Rio_readlineb(client_rio, buf, MAXLINE)>0) {
if (strcmp(buf, endof_hdr) == 0) break; // EOF처리로 빈 줄('\r\n') 만나면 헤더 끝
// 2-1. Host 헤더 찾기
if (!strncasecmp(buf, host_key, strlen(host_key))) { //Host: 일치하는 게 있으면 0으로 false이지만 !으로 true되어 if문 실행
strcpy(host_hdr, buf); // Host 헤더는 저장만 함
continue;
}
// 2-2. Connection / Proxy-Connection / User-Agent는 무시 (우리가 고정된 값 사용)
if (strncasecmp(buf, connection_key, strlen(connection_key)) &&
strncasecmp(buf, proxy_connection_key, strlen(proxy_connection_key)) &&
strncasecmp(buf, user_agent_key, strlen(user_agent_key))) {
strcat(other_hdr,buf); // 그 외 헤더들은 누적 저장
}
}
// 3. 클라이언트가 Host 헤더를 안 보낸 경우 직접 만들어준다.
if (strlen(host_hdr) == 0) {
sprintf(host_hdr,host_hdr_format,hostname);
}
// 4. 최종 HTTP 요청 헤더 구성 (엔드서버에 보낼 요청)
// 프록시 서버가 엔드 서버로 보낼 요청 헤더 작성
sprintf(http_header,"%s%s%s%s%s%s%s",
request_hdr, // GET /path HTTP/1.0
host_hdr, // Host: example.com
conn_hdr, // Connection: close
prox_hdr, // Proxy-Connection: close
user_agent_hdr, // 고정된 User-Agent
other_hdr, // 클라이언트의 기타 헤더들
endof_hdr); // 마지막 줄 "\r\n"
return ;
}connect_endServer 함수
connect_endServer() 함수는 프록시 서버가 엔드 서버에 TCP 연결을 생성하기 위한 클라이언트 소켓을 만드는 함수입니다.
인자로 받은 hostname (예: "localhost")와 port (예: 20000)을 사용하여, 해당 서버에 연결할 클라이언트 소켓을 열고 그 파일 디스크립터를 반환합니다.
처리 흐름
- 정수형 포트 번호(
int port)를 문자열(char[])로 변환 - 변환된 hostname과 port 문자열을 사용해 TCP 연결 생성
- 연결에 성공하면 연결된 소켓의 fd 반환, 실패 시 음수 반환
inline int connect_endServer(char *hostname,int port,char *http_header) {
char portStr[100];
sprintf(portStr,"%d",port); // 1. 정수형 포트 번호를 문자열로 변환 (Open_clientfd는 문자열 포트 번호를 받음)
return Open_clientfd(hostname,portStr); // 2. 엔드 서버에 연결 요청 후 연결 소켓 디스크립터(fd)를 반환
}parse_uri 함수
parse_uri함수는 URI에서 hostname, port, path를 파싱합니다.
예외처리
포트 명시가 되어 있지 않다면 기본적으로 80 포트를 사용하지만, 명시가 되어 있다면 사용자가 지정한 포트로 사용합니다.
URI 파싱
입력을 해당 함수의 파싱을 통해 다음과 같이 출력합니다.
"http://localhost:20000/index.html"
→ hostname="localhost", port=20000, path="/index.html"
void parse_uri(char *uri,char *hostname,char *path,int *port) {
*port = 80; // 기본 포트를 HTTP의 기본 포트인 80으로 설정
char* pos = strstr(uri,"//"); // "http://"이후의 위치를 찾음
pos = pos!=NULL? pos+2:uri; // "http://"이 있으면 건너뛰고, 없으면 uri 전체 사용
// hostname, port, path를 본격적으로 파싱
char *pos2 = strstr(pos,":"); // 포트 구분자 ':' 찾기
if (pos2 != NULL) { // 포트가 NULL이 아니라면 실행
*pos2 = '\0'; // ':' 위치를 기준으로 문자열 자르기
sscanf(pos,"%s",hostname); // ':' 앞 -> hostname 스캔
sscanf(pos2+1,"%d%s",port,path); // ':' 뒤 -> port와 path 스캔(포트를 80에서 클라이언트 지정 포트로 변경)
}
else { // 포트가 NULL이라면 실행
pos2 = strstr(pos,"/"); // ':'이 없으면 '/' 기준으로 분리
if (pos2!=NULL) {
*pos2 = '\0'; // '/' 앞을 hostname으로 잘라내기
sscanf(pos,"%s",hostname);
*pos2 = '/'; // '/' 을 다시 복원
sscanf(pos2,"%s",path); // '/'부터 나머지를 path로 저장
}
else {
sscanf(pos,"%s",hostname); // '/'도 없으면 전체를 hostname으로 처리
}
}
return;
}init_cache 함수
init_cache 함수는 프록시 서버에서 사용할 메모리 캐시를 초기화합니다.
총 10개의 캐시 블록을 할당하고, 각 블록에 필요한 정보를 담을 수 있도록 동적 메모리 할당을 수행합니다. 또한, 캐시 접근을 위해 세마포어 초기화도 수행합니다.
기능 모음
| 기능 | 설명 |
|---|---|
| 캐시 공간 할당 | URL, flag, cnt, content를 위한 동적 메모리 할당 |
| 블록 수 | 10개 (1MB 한도 / 블록당 100KB) |
| 세마포어 | mutex(read), w(write)용 초기화 |
| 초기값 설정 | flag = 0 (빈 캐시), cnt = 1 (LRU 용도) |
void init_cache() {
Sem_init(&mutex, 0, 1); // readcnt 값을 보호하기 위한 세마포어 초기화 (binary semaphore)
Sem_init(&w, 0, 1); // writer(쓰기 접근)를 위한 세마포어 초기화 (binary semaphore)
readcnt = 0; // 현재 읽고 있는 reader의 수를 0으로 초기화
cache = (Cache_info *)Malloc(sizeof(Cache_info) * 10); // 캐시의 최대 크기는 1MB이고 캐시의 객체는 최대 크기가 100KB이라서 10개의 공간을 동적할당
for (int i = 0; i < 10; i++) {
cache[i].url = (char *)Malloc(sizeof(char) * 256); // URL 저장 공간 (최대 256바이트)
cache[i].flag = (int *)Malloc(sizeof(int)); // 캐시 사용 여부 플래그 4바이트 저장
cache[i].cnt = (int *)Malloc(sizeof(int)); // LRU(Latest Recently Used) 순서 추적용(얼마나 사용되지 않았나) 4바이트
cache[i].content = (char *)Malloc(sizeof(char) * MAX_OBJECT_SIZE); // 실제 콘텐츠 저장 공간 100KB 할당
*(cache[i].flag) = 0; // flag 0 → 사용되지 않은 상태로 설정
*(cache[i].cnt) = 1; // LRU 용으로 cnt +1로 증가 설정, 최근에 찾은 것일 수록 0이랑 가까움
}
}reader 함수
reader 함수는 클라이언트 요청 URL이 프록시 서버의 캐시에 존재하는지 확인하고, 존재하면 그 캐시 내용을 클라이언트에게 보내는 읽기 전용 캐시 탐색기입니다.
- 있음: 캐시 내용 전송 (cache hit)
- 없음: 아무 일도 하지 않음 (cache miss)
- 동시에 여러 스레드가 읽을 수 있도록 세마포어로 동기화 처리
기능
| 구분 | 설명 |
|---|---|
| 함수 목적 | 요청한 URL이 이미 캐시에 존재하는지 확인하고, 있다면 클라이언트에 데이터를 바로 전송 (캐시 읽기) |
| 동기화 방식 | mutex 세마포어를 사용해 readcnt 값을 동기화하고, readcnt가 처음 1일 때 w 세마포어로 쓰기를 차단 |
| 캐시 탐색 방식 | 캐시 배열을 선형 순회하며 URL이 일치하는 항목 탐색 |
| 응답 방식 | 일치하는 항목이 있으면 클라이언트 connfd로 캐시 내용 전송 |
| 방문 정보 갱신 | 해당 캐시 블록의 cnt 값을 1로 초기화 (최근 방문 표시) |
나머지 블록들의 cnt는 모두 +1 (방문 안한 기간 증가) |
|
| 반환값 | 캐시에 존재하면 1, 없으면 0 반환 |
처리 흐름
P(&mutex)→readcnt++readcnt == 1이면P(&w)로 쓰기 차단V(&mutex)- 읽기 진입- 캐시 10개 블록 순회
flag == 1이고,url이 일치하면 → 캐시 내용 클라이언트로 전송 →cnt = 1,return_flag = 1 - 모든 캐시 블록의
cnt+= 1 → 캐시 사용 우선순위 조정 (LRU 기반) P(&mutex)→readcnt-- readcnt == 0이면V(&w)로 쓰기 허용V(&mutex)- 읽기 종료- 결과 반환:
return_flag(1 or 0)
// cache에서 요청한 url 있는지 찾는 함수
// 세마포어를 이용해서 reader가 먼저 되고 여러 thread가 읽고 있으면 writer는 할 수가 없게함
int reader(int connfd, char *url) {
int return_flag = 0; // 캐시에서 찾았으면 1, 못 찾았으면 0 (return 값으로 사용됨)
P(&mutex); // readcnt를 보호하기 위해 mutex 진입
readcnt++; // 첫 번째 reader는 writer를 막기 위해 write 세마포어 획득
if(readcnt == 1) {
P(&w);
}
V(&mutex); // 뮤텍스 해제
// 캐시를 다 돌면서 캐시에 써있고 캐시의 URL과 현재 요청한 URL이 같으면,
// 클라이언트 디스크립터에 캐시의 내용을 쓰고 해당 캐시의 cnt를 0으로 초기화 후 break 실행
for(int i = 0; i < 10; i++) {
// flag가 1이면 해당 캐시 블록이 사용중이고, strcmp로 URL과 비교하여 일치하면 Hit
if(*(cache[i].flag) == 1 && !strcmp(cache[i].url, url)) {
Rio_writen(connfd, cache[i].content, MAX_OBJECT_SIZE); // 클라이언트에게 캐시 데이터 전송
return_flag = 1; // flag 1로 캐시 Hit 표시
*(cache[i].cnt) = 1; // LRU 정책에 따라 cnt 0으로 초기화 (최근사용)
break;
}
}
// 모든 캐시 객체의 cnt를 +1 함. 즉, 방문안한 일수를 올려줌
for(int i = 0; i < 10; i++) {
(*(cache[i].cnt))++; // 모든 캐시 블록의 cnt 증가 (오래된 정도 반영)
}
P(&mutex); // readcnt 접근을 위한 mutex 진입
readcnt--; // reader 수 감소
if(readcnt == 0) { // 마지막 reader가 나갈 때, writer에게 문을 열어준다
V(&w);
}
V(&mutex); // mutex가 해제된다
return return_flag; // 캐시 Hit 여부를 반환한다(1 또는 0)
}더알아보기(mutex)
mutex는 Mutual Exclusion (상호 배제)로 여러 스레드 중 한 번에 하나만 특정 코드(임계 영역, critical section)에 들어가도록 보장합니다.
이로 인해 스레드가 동시에 변경하려고 할 때 문제(값 꼬임)가 생기지 않도록 mutex를 통해 잠가서 보호를 합니다.
→ mutex는 공유 자원을 여러 스레드가 동시에 사용하지 못하도록 막는 장치
주로 사용하는 라이브러리는 pthread_mutex_t (POSIX 스레드 라이브러리)와 sem_t (세마포어 기반)도 뮤텍스처럼 사용 가능합니다.
예시
P(&mutex); // 진입 - 다른 스레드 접근 막음
readcnt++; // 공유 변수 readcnt를 안전하게 증가
V(&mutex); // 해제 - 다른 스레드 진입 허용- 위 코드는
readcnt를 여러 스레드가 동시에 변경하려고 할 때 문제가 생기지 않도록 mutex로 잠그는 것입니다. - 예로 두 스레드가 동시에
readcnt++를 실행하면, 값이 꼬일 수 있기 때문에 이렇게 동기화가 필요합니다.
→ 이렇게 프록시 서버 코드에서 mutex는 readcnt라는 공유 카운터를 안전하게 읽고 수정하기 위해 사용됩니다.
mutex vs 세마포어
| 항목 | mutex (pthread_mutex) |
세마포어 (sem_t) |
|---|---|---|
| 소유권 | 스레드가 소유 (lock/unlock) | 시스템 자원 기반 (wait/signal) |
| 값 | 항상 0 또는 1 | 0 이상 정수 |
| 용도 | 임계 영역 보호 | 카운팅, 생산자-소비자 문제 등 |
writer 함수
writer 함수는 클라이언트가 요청한 결과를 캐시에 저장하는 함수입니다.
만약 캐시에 빈 공간이 있으면 그곳에 저장하고, 없다면 가장 오래 전에 사용된 캐시 블록을 덮어씌웁니다.
→ 일종의 LRU 알고리즘 구현
기능
| 구분 | 설명 |
|---|---|
| 함수 목적 | 프록시 서버가 받은 HTTP 응답을 캐시에 저장하여, 다음 요청 시 빠르게 응답하기 위함 (캐시 쓰기) |
| 동기화 방식 | w 세마포어를 사용하여 단일 스레드만 캐시에 쓰기 가능하도록 보장 (writer-writer 간 경쟁 방지) |
| 캐시 위치 선정 | 1. 비어 있는 캐시 블록이 있다면 그 위치에 저장2. 없다면 가장 오래 전에 사용된 블록(LRU 방식)을 덮어쓰기 |
| 저장 내용 | - 요청 URL (url) - 응답 데이터 (buf) - 캐시 사용 플래그 (flag = 1) - 최근 사용 표시 (cnt = 1) |
| 알고리즘 | 일종의 LRU(Least Recently Used) 알고리즘 기반으로 가장 오랫동안 사용되지 않은 캐시 블록 교체 |
| 세마포어 해제 | 캐시 쓰기가 끝나면 V(&w) 호출하여 다른 쓰기 작업 허용 |
처리 흐름
P(&w): 쓰기 진입을 위해 세마포어 대기- 캐시 블록 중 빈 공간 또는 오래된 블록 선택
- 선택된 캐시 블록에 URL, 데이터 저장
- 해당 블록을 활성화 (
flag = 1) - 최근 사용 표시 (
cnt = 1) V(&w): 세마포어 해제로 쓰기 종료
// 캐시에서 요청한 URL의 정보 쓰기
// 세마포어를 이용해서 writer는 한번 수행함
void writer(char *url, char *buf) {
P(&w); // 쓰기 작업 전, 세마포어 w를 통해 진입 제한(여러 스레드가 동시 캐시 수정 x토록 동기화)
int idx = 0; // 데이터를 저장할 캐시 인덱스
int max_cnt = 0; // 현재까지 방문 안한 최대 일수 cnt(가장 오래된 캐시 찾기)
// 10개의 캐시를 돌고 만약 비어있는 곳이 있으면 비어있는 곳에 index를 찾고,
// 없으면 가장 오래 방문 안한 곳의 index 찾음
for(int i = 0; i < 10; i++) {
if(*(cache[i].flag) == 0) { // 캐시 블록이 비어 있는 경우
idx = i; // 해당 인덱스를 선택
break; // 더 이상 탐색 X
}
if(*(cache[i].cnt) > max_cnt) { // 가장 오래전에 사용된 캐시 블록을 찾음 (cnt가 가장 큰 것)
idx = i; // 현재 인덱스 선택
max_cnt = *(cache[i].cnt); // 최대 cnt 갱신
}
}
// 선택한 캐시 블록에 데이터 저장
*(cache[idx].flag) = 1; // 캐시 블록이 사용 중임을 표시
strcpy(cache[idx].url, url); // 요청 URL 저장
strcpy(cache[idx].content, buf); // 응답 데이터 저장
*(cache[idx].cnt) = 1; // 최근 사용했음을 나타내기 위해 cnt를 1로 초기화
V(&w); // writer 세마포어를 올려서 다른 스레드들이 캐시에 접근 가능하게 함
}proxy.c 종합
#include <stdio.h>
#include "csapp.h" // csapp 라이브러리는 CS:APP 교재에서 제공하는 네트워크 및 시스템 프로그래밍 지원 함수 모음입니다.
/* Recommended max cache and object sizes */
#define MAX_CACHE_SIZE 1049000 // 캐시 전체 최대 크기 (약 1MB)
#define MAX_OBJECT_SIZE 102400 // 한 객체의 최대 크기 (약 100KB)
/* You won't lose style points for including this long line in your code */
// 프록시 서버가 요청할 때 사용하는 User-Agent 헤더
static const char *user_agent_hdr =
"User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 "
"Firefox/10.0.3\r\n";
// 연결을 닫도록 지정하는 HTTP 헤더
static const char *conn_hdr = "Connection: close\r\n";
static const char *prox_hdr = "Proxy-Connection: close\r\n";
// Host 헤더를 만들기 위한 형식 문자열
static const char *host_hdr_format = "Host: %s\r\n";
// GET 요청을 위한 형식 문자열
static const char *requestlint_hdr_format = "GET %s HTTP/1.0\r\n";
// HTTP 요청 헤더의 끝을 나타낸다.
static const char *endof_hdr = "\r\n";
// 특정 헤더 이름을 비교할 때 사용하기 위한 문자열 상수
static const char *connection_key = "Connection";
static const char *user_agent_key= "User-Agent";
static const char *proxy_connection_key = "Proxy-Connection";
static const char *host_key = "Host";
// 클라이언트 요청을 처리하는 함수
void doit(int connfd);
// URI를 호스트명, 경로(path), 포트로 분해하는 함수
void parse_uri(char *uri,char *hostname,char *path,int *port);
// 클라이언트의 요청을 바탕으로 서버에 보낼 HTTP 헤더를 작성하는 함수
void build_http_header(char *http_header,char *hostname,char *path,int port, rio_t *client_rio);
// 엔드서버와 연결하는 함수
int connect_endServer(char *hostname,int port,char *http_header);
// 멀티스레딩 처리를 위한 함수
void *thread(void *vargsp);
// functions for caching
void init_cache(void); // 캐시 초기화
int reader(int connfd, char *url); // 클라이언트가 요청한 URL이 캐시에 존재하는지 확인하고 데이터를 전송하는 함수 (리더 역할)
void writer(char *url, char *buf); // 새 데이터를 캐시에 저장하는 함수 (라이터 역할)
// 개별 캐시 블록 정보를 담을 구조체
typedef struct {
char *url; // 요청된 URL
int *flag; // 캐시 블록이 사용 중인지 아닌지 표시 (0: 빈 블록, 1: 사용 중)
int *cnt; // 사용 빈도 또는 LRU 정책을 위한 카운트
int *content; // 실제 응답 데이터를 저장하는 공간 (클라이언트에 보낼 내용)
} Cache_info;
Cache_info *cache; // 캐시 전체를 담을 포인터 배열
int readcnt; // 동시에 읽는 reader 수를 관리하기 위한 변수
sem_t mutex, w; // 세마포어: mutex는 reader 수 갱신, w는 writer 접근 제어용
int main(int argc, char **argv) {
// 포트 번호가 입력되지 않았을 시, 사용법 출력
if(argc != 2) {
fprintf(stderr, "usage :%s <port> \n", argv[0]);
exit(1);
}
init_cache(); // 캐시 초기화 함수 호출
int listenfd, connfd;
socklen_t clientlen;
char hostname[MAXLINE], port[MAXLINE];
struct sockaddr_storage clientaddr;
pthread_t tid;
listenfd = Open_listenfd(argv[1]); //클라이언트로부터 연결을 수신할 소켓을 열고 대기 상태로 만든다.
// 무한 루프: 클라이언트의 연결 요청을 지속적으로 수락
while(1) {
clientlen = sizeof(clientaddr);
// 클라이언트의 연결 요청을 수락하고, 연결된 소켓의 파일 디스크립터 변환
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen);
// 연결된 클라이언트의 호스트명과 포트 정보를 가져온다
Getnameinfo((SA*)&clientaddr, clientlen, hostname, MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s %s).\n",hostname, port);
// 새로운 스레드를 생성하여 클라이언트 요청을 처리 (connfd를 인자로 전달)
Pthread_create(&tid, NULL, thread, (void *)connfd);
}
return 0;
}
void *thread(void *vargs) {
int connfd = (int)vargs; // main 함수에서 전달받은 연결 소켓 번호를 정수형으로 변환
Pthread_detach(pthread_self()); // 현재 스레드를 분리 상태로 설정하고, 스레드 종료시 자동으로 자원이 반환되어 메모리 누수 방지함
doit(connfd); // 클라이언트 요청 처리 (HTTP 요청을 파싱하고 응답 생성 등 역할)
Close(connfd); // 처리 후 클라이언트 소켓 닫음
}
void doit(int connfd) {
int end_serverfd; // 엔드서버(tiny.c)와 연결된 파일 디스크립터
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE]; // 요청 라인을 저장할 변수들
char endserver_http_header[MAXLINE]; // 엔드서버에 보낼 최종 HTTP 헤더
// URI 파싱을 통해 추출할 값들
char hostname[MAXLINE], path[MAXLINE];
int port;
rio_t rio, server_rio; // 클라이언트와 통신할 rio / 엔드서버와 통신할 rio 선언
char url[MAXLINE]; // 요청받은 URL 저장용
char content_buf[MAX_OBJECT_SIZE]; // 캐시에 저장할 응답 데이터 버퍼
// 1. 클라이언트 요청 라인 읽기: ex) GET http://localhost:8000/home.html HTTP/1.1
Rio_readinitb(&rio, connfd); // 클라이언트 소켓에 대해 rio 초기화
Rio_readlineb(&rio, buf, MAXLINE); // 요청 라인 한 줄 읽기
sscanf(buf, "%s %s %s", method, uri, version); // (메서드, URI, 버전) 파싱
strcpy(url, uri); // 캐시 키로 사용할 URL 복사
// 2. GET 요청만 지원함 (다른 메서드 무시)
if (strcasecmp(method, "GET")) { // method가 GET으로 같으면 0(false)를 반환함 즉, 다르다면 출력함
printf("Proxy does not implement the method"); // 에러 출력
return;
}
// 3. 캐시에 해당 요청 결과가 있는지 확인 (있으면 클라이언트에 바로 응답 후 종료)
if (reader(connfd, url)) {
return ;
}
// 4. URI를 파싱하여 hostname(localhost), path, port(20000) 추출
// 프록시 서버가 엔드 서버로 보낼 정보들을 파싱
parse_uri(uri, hostname, path, &port);
// 5. 엔드서버에 보낼 요청 헤더 구성 (GET /path HTTP/1.0 + Host + User-Agent 등)
// 프록시 서버가 엔드 서버로 보낼 요청 헤더들을 만든다. endserver_http_header가 채워짐
build_http_header(endserver_http_header, hostname, path, port, &rio);
// 6. 엔드서버에 연결 시도
// 프록시 서버와 엔드 서버를 연결함
end_serverfd = connect_endServer(hostname, port, endserver_http_header); // 프록시 측에서 엔드 서버로 연결된 clinetfd
if (end_serverfd < 0) {
printf("connection failed\n"); // 연결 실패시 종료
return;
}
// 7. 엔드서버에 HTTP 요청 헤더 전송
Rio_readinitb(&server_rio, end_serverfd); // 엔드서버와 소켓에 대해 rio 초기화
Rio_writen(end_serverfd, endserver_http_header, strlen(endserver_http_header)); // HTTP 요청 헤더 전송
// 8. 엔드서버의 응답 메시지를 읽어서 클라이언트에 보내고, content_buf에 복사
size_t n;
int total_size = 0; // content_buf에 저장한 총 크기 (캐시용)
while((n = Rio_readlineb(&server_rio,buf, MAXLINE)) != 0) {
printf("proxy received %d bytes,then send\n",n); // 디버깅 로그
Rio_writen(connfd, buf, n); // 클라이언트에 응답 전달
// connfd -> client와 proxy 연결 소켓. proxy 관점.
// 캐시 버퍼에 응답 내용 저장 (최대 크기 초과하지 않도록)
if (total_size + n < MAX_OBJECT_SIZE) {
strcpy(content_buf + total_size, buf);
}
total_size += n;
}
// 9. 전체 응답 크기가 MAX_OBJECT_SIZ 보다 작으면 캐시에 저장
if (total_size < MAX_OBJECT_SIZE) {
writer(url, content_buf);
}
// 10. 엔드서버와 연결 종료
Close(end_serverfd);
}
void build_http_header(char *http_header,char *hostname,char *path,int port,rio_t *client_rio) {
char buf[MAXLINE],request_hdr[MAXLINE],other_hdr[MAXLINE],host_hdr[MAXLINE];
/* 요청 헤더 초기화 */
memset(buf, 0, MAXLINE);
memset(request_hdr, 0, MAXLINE);
memset(other_hdr, 0, MAXLINE);
memset(host_hdr, 0, MAXLINE);
// 1. 요청 라인 작성: ex) GET /index.html HTTP/1.0
sprintf(request_hdr, requestlint_hdr_format, path);
// 2. 클라이언트 요청 헤더 읽으면서 필요한 부분만 필터링
// 클라이언트 요청 헤더들에서 Host header와 나머지 header들을 구분해서 넣어줌
while(Rio_readlineb(client_rio, buf, MAXLINE)>0) {
if (strcmp(buf, endof_hdr) == 0) break; // EOF처리로 빈 줄('\r\n') 만나면 헤더 끝
// 2-1. Host 헤더 찾기
if (!strncasecmp(buf, host_key, strlen(host_key))) { //Host: 일치하는 게 있으면 0으로 false이지만 !으로 true되어 if문 실행
strcpy(host_hdr, buf); // Host 헤더는 저장만 함
continue;
}
// 2-2. Connection / Proxy-Connection / User-Agent는 무시 (우리가 고정된 값 사용)
if (strncasecmp(buf, connection_key, strlen(connection_key)) &&
strncasecmp(buf, proxy_connection_key, strlen(proxy_connection_key)) &&
strncasecmp(buf, user_agent_key, strlen(user_agent_key))) {
strcat(other_hdr,buf); // 그 외 헤더들은 누적 저장
}
}
// 3. 클라이언트가 Host 헤더를 안 보낸 경우 직접 만들어준다.
if (strlen(host_hdr) == 0) {
sprintf(host_hdr,host_hdr_format,hostname);
}
// 4. 최종 HTTP 요청 헤더 구성 (엔드서버에 보낼 요청)
// 프록시 서버가 엔드 서버로 보낼 요청 헤더 작성
sprintf(http_header,"%s%s%s%s%s%s%s",
request_hdr, // GET /path HTTP/1.0
host_hdr, // Host: example.com
conn_hdr, // Connection: close
prox_hdr, // Proxy-Connection: close
user_agent_hdr, // 고정된 User-Agent
other_hdr, // 클라이언트의 기타 헤더들
endof_hdr); // 마지막 줄 "\r\n"
return ;
}
// 프록시 서버와 엔드 서버 연결
inline int connect_endServer(char *hostname,int port,char *http_header) {
char portStr[100];
sprintf(portStr,"%d",port); // 1. 정수형 포트 번호를 문자열로 변환 (Open_clientfd는 문자열 포트 번호를 받음)
return Open_clientfd(hostname,portStr); // 2. 엔드 서버에 연결 요청 후 연결 소켓 디스크립터(fd)를 반환
}
void parse_uri(char *uri,char *hostname,char *path,int *port) {
*port = 80; // 기본 포트를 HTTP의 기본 포트인 80으로 설정
char* pos = strstr(uri,"//"); // "http://"이후의 위치를 찾음
pos = pos!=NULL? pos+2:uri; // "http://"이 있으면 건너뛰고, 없으면 uri 전체 사용
// hostname, port, path를 본격적으로 파싱
char *pos2 = strstr(pos,":"); // 포트 구분자 ':' 찾기
if (pos2 != NULL) { // 포트가 NULL이 아니라면 실행
*pos2 = '\0'; // ':' 위치를 기준으로 문자열 자르기
sscanf(pos,"%s",hostname); // ':' 앞 -> hostname 스캔
sscanf(pos2+1,"%d%s",port,path); // ':' 뒤 -> port와 path 스캔(포트를 80에서 클라이언트 지정 포트로 변경)
}
else { // 포트가 NULL이라면 실행
pos2 = strstr(pos,"/"); // ':'이 없으면 '/' 기준으로 분리
if (pos2!=NULL) {
*pos2 = '\0'; // '/' 앞을 hostname으로 잘라내기
sscanf(pos,"%s",hostname);
*pos2 = '/'; // '/' 을 다시 복원
sscanf(pos2,"%s",path); // '/'부터 나머지를 path로 저장
}
else {
sscanf(pos,"%s",hostname); // '/'도 없으면 전체를 hostname으로 처리
}
}
return;
}
// cache 초기화
void init_cache() {
Sem_init(&mutex, 0, 1); // readcnt 값을 보호하기 위한 세마포어 초기화 (binary semaphore)
Sem_init(&w, 0, 1); // writer(쓰기 접근)를 위한 세마포어 초기화 (binary semaphore)
readcnt = 0; // 현재 읽고 있는 reader의 수를 0으로 초기화
cache = (Cache_info *)Malloc(sizeof(Cache_info) * 10); // 캐시의 최대 크기는 1MB이고 캐시의 객체는 최대 크기가 100KB이라서 10개의 공간을 동적할당
for (int i = 0; i < 10; i++) {
cache[i].url = (char *)Malloc(sizeof(char) * 256); // URL 저장 공간 (최대 256바이트)
cache[i].flag = (int *)Malloc(sizeof(int)); // 캐시 사용 여부 플래그 4바이트 저장
cache[i].cnt = (int *)Malloc(sizeof(int)); // LRU(Latest Recently Used) 순서 추적용(얼마나 사용되지 않았나) 4바이트
cache[i].content = (char *)Malloc(sizeof(char) * MAX_OBJECT_SIZE); // 실제 콘텐츠 저장 공간 100KB 할당
*(cache[i].flag) = 0; // flag 0 → 사용되지 않은 상태로 설정
*(cache[i].cnt) = 1; // LRU 용으로 cnt +1로 증가 설정, 최근에 찾은 것일 수록 0이랑 가까움
}
}
// cache에서 요청한 url 있는지 찾는 함수
// 세마포어를 이용해서 reader가 먼저 되고 여러 thread가 읽고 있으면 writer는 할 수가 없게함
int reader(int connfd, char *url) {
int return_flag = 0; // 캐시에서 찾았으면 1, 못 찾았으면 0 (return 값으로 사용됨)
P(&mutex); // readcnt를 보호하기 위해 mutex 진입
readcnt++; // 첫 번째 reader는 writer를 막기 위해 write 세마포어 획득
if(readcnt == 1) {
P(&w);
}
V(&mutex); // 뮤텍스 해제
// 캐시를 다 돌면서 캐시에 써있고 캐시의 URL과 현재 요청한 URL이 같으면,
// 클라이언트 디스크립터에 캐시의 내용을 쓰고 해당 캐시의 cnt를 0으로 초기화 후 break 실행
for(int i = 0; i < 10; i++) {
// flag가 1이면 해당 캐시 블록이 사용중이고, strcmp로 URL과 비교하여 일치하면 Hit
if(*(cache[i].flag) == 1 && !strcmp(cache[i].url, url)) {
Rio_writen(connfd, cache[i].content, MAX_OBJECT_SIZE); // 클라이언트에게 캐시 데이터 전송
return_flag = 1; // flag 1로 캐시 Hit 표시
*(cache[i].cnt) = 1; // LRU 정책에 따라 cnt 0으로 초기화 (최근사용)
break;
}
}
// 모든 캐시 객체의 cnt를 +1 함. 즉, 방문안한 일수를 올려줌
for(int i = 0; i < 10; i++) {
(*(cache[i].cnt))++; // 모든 캐시 블록의 cnt 증가 (오래된 정도 반영)
}
P(&mutex); // readcnt 접근을 위한 mutex 진입
readcnt--; // reader 수 감소
if(readcnt == 0) { // 마지막 reader가 나갈 때, writer에게 문을 열어준다
V(&w);
}
V(&mutex); // mutex 해제
return return_flag; // 캐시 Hit 여부를 반환한다(1 또는 0)
}
// 캐시에서 요청한 URL의 정보 쓰기
// 세마포어를 이용해서 writer는 한번 수행함
void writer(char *url, char *buf) {
P(&w); // 쓰기 작업 전, 세마포어 w를 통해 진입 제한(여러 스레드가 동시 캐시 수정 x토록 동기화)
int idx = 0; // 데이터를 저장할 캐시 인덱스
int max_cnt = 0; // 현재까지 방문 안한 최대 일수 cnt(가장 오래된 캐시 찾기)
// 10개의 캐시를 돌고 만약 비어있는 곳이 있으면 비어있는 곳에 index를 찾고,
// 없으면 가장 오래 방문 안한 곳의 index 찾음
for(int i = 0; i < 10; i++) {
if(*(cache[i].flag) == 0) { // 캐시 블록이 비어 있는 경우
idx = i; // 해당 인덱스를 선택
break; // 더 이상 탐색 X
}
if(*(cache[i].cnt) > max_cnt) { // 가장 오래전에 사용된 캐시 블록을 찾음 (cnt가 가장 큰 것)
idx = i; // 현재 인덱스 선택
max_cnt = *(cache[i].cnt); // 최대 cnt 갱신
}
}
// 선택한 캐시 블록에 데이터 저장
*(cache[idx].flag) = 1; // 캐시 블록이 사용 중임을 표시
strcpy(cache[idx].url, url); // 요청 URL 저장
strcpy(cache[idx].content, buf); // 응답 데이터 저장
*(cache[idx].cnt) = 1; // 최근 사용했음을 나타내기 위해 cnt를 1로 초기화
V(&w); // writer 세마포어를 올려서 다른 스레드들이 캐시에 접근 가능하게 함
}코드 실행법(테스트법)
만약, 해당 포트가 열려있지 않으면 포트포워딩을 통해 열어 주셔야합니다.
[방법 1] 터미널에서 자체 테스트
- tiny와 proxy을
make명령어나 gcc 명령어로 컴파일합니다. ./tiny 10000(포트번호는 자유) 로 tiny 서버를 실행시킵니다. (터미널 1)./proxy 20000(포트번호는 tiny와 안겹치게) 로 proxy 서버를 실행시킵니다.(터미널 2)- 해당 명령어를 터미널에 작성하여 실행시킵니다. (터미널 3)
curl --proxy http://localhost:10000/ http://localhost:20000/

위 사진처럼 나오면 테스트 성공입니다.
[방법 2] 동봉된 ./driver.sh 로 자동 테스트하기(70점 만점)
- 테스트를 위해 net-tools 를 먼저 설치해줍니다.
- 만약, make를 하지 않았다면 프록시 서버를 make를 통해 컴파일합니다.
./proxy 20000(포트번호는 자유) 로 proxy 서버를 실행시킵니다. (터미널 1)./driver.sh로 테스트를 수행합니다. (터미널 2)
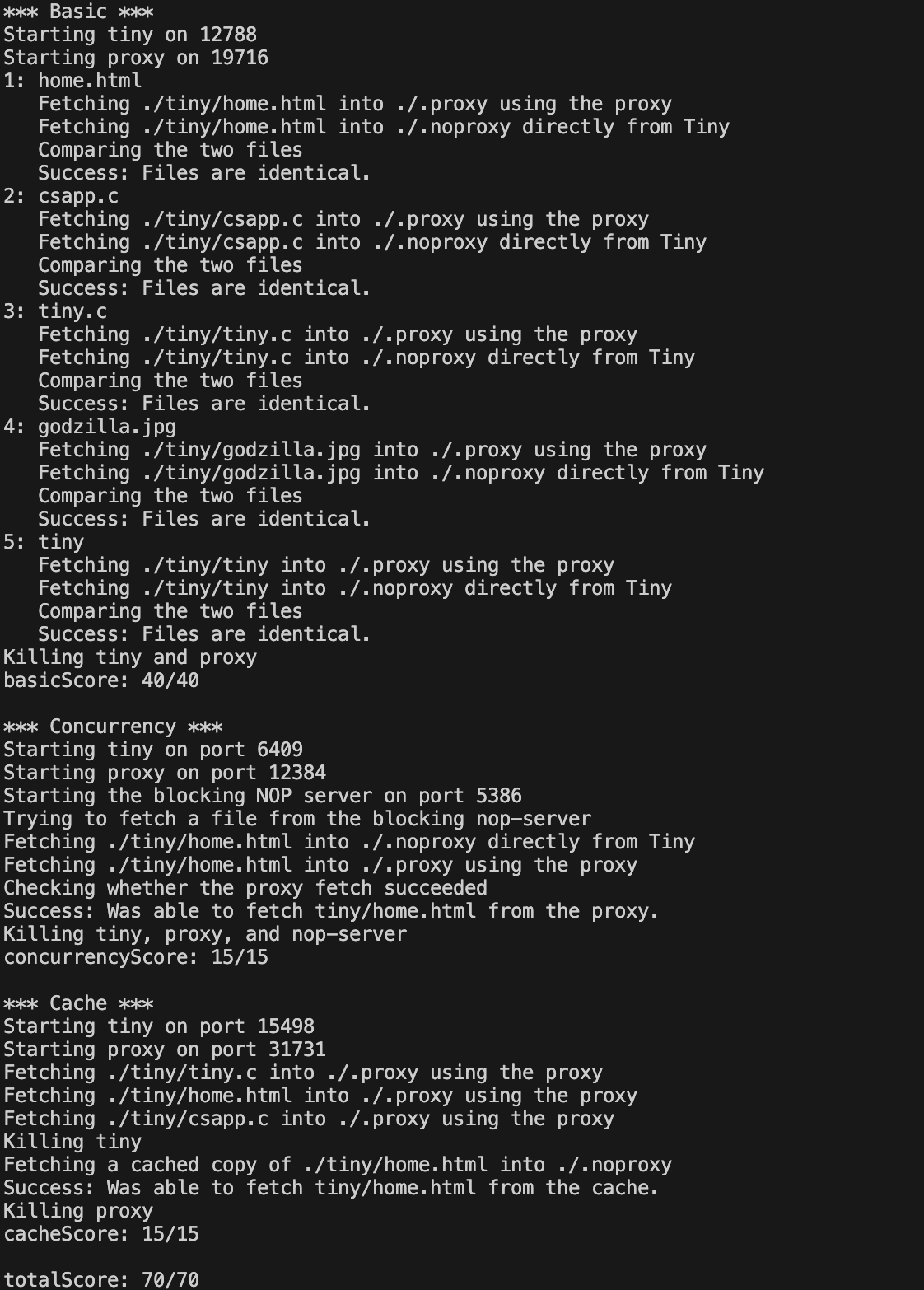
이런식으로 출력된다면 테스트 성공입니다. 구현 정도에 따라 점수는 달라집니다.(캐시기능을 빼먹었다던가…)
Proxy 전체 내용 요약 정리 노트
함수 구조
| 구성 요소 | 역할 |
|---|---|
main 함수 |
서버 초기화 및 클라이언트 연결 수락, 스레드 생성 |
thread 함수 |
클라이언트 요청을 처리하는 독립적인 스레드 실행 |
doit 함수 |
요청을 파싱하고, 캐시 확인 후 엔드서버와 통신 |
reader, writer |
캐시 읽기/쓰기 (동기화 보장) |
build_http_header |
클라이언트 요청을 기반으로 엔드서버에 보낼 헤더 생성 |
parse_uri, connect_endServer |
URI 파싱 및 엔드서버 연결 |
init_cache |
캐시 초기화 |
동작 흐름
1. 프록시 서버 실행 (main)
- 사용자가 포트 번호를 인자로 실행 (
./proxy 12345) init_cache()로 캐시 초기화- 클라이언트 접속을 기다리며 반복 (
while)
2. 클라이언트 접속
- 클라이언트가 연결하면
Accept로 소켓 수락 - 스레드 생성 (
pthread_create) →thread함수 호출
3. 요청 처리 스레드 (thread)
- 연결된 소켓(
connfd)을 인자로 받아doit(connfd)호출 - 스레드는 분리(
detach)되어 자동 종료됨
4. 클라이언트 요청 처리 (doit)
- 클라이언트로부터 HTTP 요청 메시지를 읽음
- 요청 method가
GET인지 확인 - 요청 URI를 파싱 →
hostname,path,port추출 - 요청 URL이 캐시에 있는지 확인 (
reader)- 있으면 캐시 응답 반환 후 함수 종료
- 엔드서버용 HTTP 요청 헤더 생성 (
build_http_header) - 엔드서버에 연결 (
connect_endServer) - 엔드서버에 요청 전송, 응답을 받아 클라이언트에게 전달
- 동시에 응답 내용을
content_buf에 저장 - 응답이
MAX_OBJECT_SIZE이하이면 캐시에 저장 (writer) - 엔드서버와 연결 종료
캐시 처리 흐름
캐시 읽기 (reader)
- 다중 스레드에서도 안전하게 캐시에 접근하도록 동기화
- URL이 존재하면 클라이언트에게 응답을 바로 보내고 종료
캐시 쓰기 (writer)
- 비어있는 캐시 슬롯이나 가장 오래된 항목을 찾아 교체
- 캐시에 URL, 내용 저장 및 방문 시간 초기화
🔐 mutex, w 세마포어를 통해 읽기-쓰기 동기화 (Reader-Writer 문제 해결)
프록시 서버 설계 특징
| 항목 | 설명 |
|---|---|
| 멀티스레드 | 여러 클라이언트 요청을 동시에 처리 가능 |
| 동기화된 캐시 | 세마포어로 캐시 일관성 유지 |
| 성능 최적화 | 자주 요청되는 데이터는 캐시로 빠르게 응답 |
| 모듈화된 구조 | 각 기능이 함수로 잘 분리되어 유지보수 용이 |