4주차 컴퓨터시스템(챕터3 ~ 3-3까지)
3장에서는 기계어 코드와 기계어 코드의 읽기 쉬운 형태인 어셈블리 코드에 대해 자세히 알아봅니다.
기계어 코드를 배워야하는 이유는 무엇인가? 어셈블리 코드를 이해하면 컴파일러의 최적화 성능을 알 수 있으며, 코드에 내재된 비효율성을 분석할 수 있습니다. 원리를 알고 있으니 프로그래밍하는데 큰 도움이 됩니다.
+하드웨어를 사용하기위해서 고급언어를 컴파일러가 해석을 할 때 환경에 따라 다르기 때문에 기계어 코드를 배워야한다. 고급언어의 추상화 때문에, 어셈블리어 컴파일을 보면서 자바코드를 효율적으로 수정할 수 있다.
그렇기 때문에 어셈블리어를 배우고, C프로그램이 어떻게 기계어 코드 형태로 컴파일되는지 공부합니다. C코드로 표현된 계산에 대해서 최적화 컴파일러는 실행 순서를 조정, 불필요한 계산 제거, 느린 연산을 빠른 연산으로 교체, 재귀적 연산은 반복 연산으로 바꾸기도 합니다. 이것을 역엔지니어링의 일종입니다.
앞으로는 보통 x86-64에 기초해서 설명합니다. 요즘에는 64비트 운영체제로 수만 바이트의 메모리와 저장공간을 처리할 수 있었지만, 옛날에는 32비트 운영체제로 4기가바이트가 극한의 메모리 크기였다는 것을 생각하며 책을 읽어야한다. (가상화 메모리때도 현재 컴퓨터 기준으로 생각해서 골머리를 앓았었다)
3-1 역사적 관점
유명한 인텔이 x86 프로세서를 개발해왔다. 맨 처음에는 16비트 마이크로 프로세서를 IC기술의 제한적인 용량 때문에 절충하며 제작했지만, 시간이 지나면서 고성능 프로세서를 만들었다.
최초의 단일 칩 16비트 8086 프로세서 부터 그 유명한 펜티엄 프로세서, 하스웰까지 오면서 32비트에서 64비트로 확장하고 부동소스점 내장, 하이퍼 쓰레딩 추가, 인스트럭션 집합 개선 등 수많은 과정을 거치고 기능을 추가하면서 오늘날에 프로세서를 만들어나갔다. 과정이나 프로세서 리스트가 궁금하면 인터넷에 좀만 찾아봐도 나온다. 인텔의 경쟁사인 AMD도 프로세서를 만들었지만, 성능이 뒤저졌기 때문에 좀 더 저렴한 가격으로 출시하여 시장 경쟁력을 가지게 되었다. 또한 2002년에 최초로 1GHz 클럭 속도 장벽을 허물면서 더 좋은 프로세서로도 평가되기도 했다.(개인적으로 요즘에는 인텔의 부진으로 AMD가 더 우수하다고 평가된다) 해당 책에서는 주로 인텔 프로세서 기준으로 기술하지만, 경쟁사인 AMD의 경우도 동일하게 적용되는 내용이 많다.
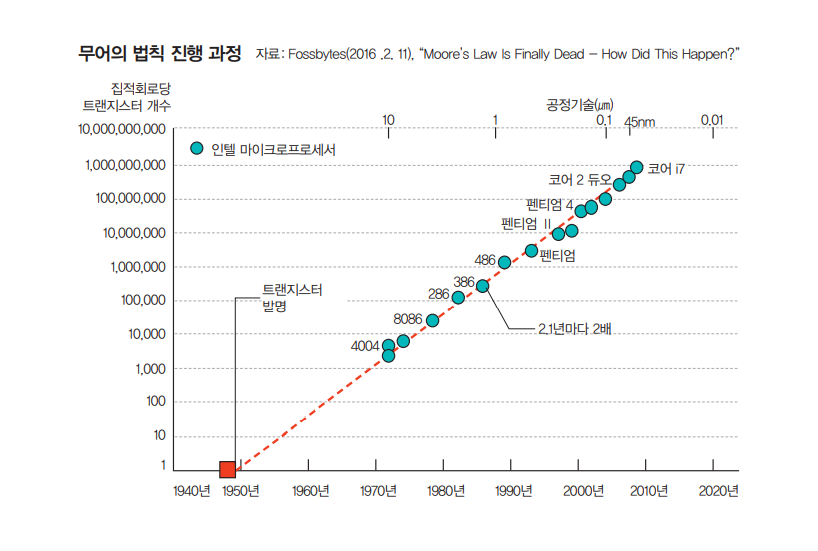
여기서 Moore의 법칙이라는게 있는데, 대강 반도체기업이 칩당 트랜지스터 수가 향후 10년간 매년 두 배씩 증가하리라는 것을 예측했다. 근데, 현실은 50년간 18개월마다 트랜지스터수를 두 배로 늘릴수 있었다. 예측이 틀린 것이다.근데 이 유사한 지수 증가율이 자기디스크와 반도체 메모리를 포함하는 컴퓨터 관련 다른 측면에서도 일어났다. 이 사실을 통해 칩당 트랜지스터를 올리는 것 보다 여러개의 코어로 멀티코어 처리를 하는게 성능향상에 득이 있어서 멀티코어로 CPU의 성능향상을 이뤄냈다.
3-2 프로그램의 인코딩
C 프로그램을 파일 p1.c, p2.c 에 작성한다고 하면
linux> gcc -Og -o p p1.c p2.c이렇게 유닉스 커맨드로 컴파일 할 수 있다.
명령어는 GCC C 컴파일러를 지정한다. 커맨드 라인 옵션으로 -0g을 주면 컴파일러는 본래 C 코드의 전체 구조를 따르는 기계어 코드를 생성하는 최적화 수준을 적용한다. 앞으로는 이러한 -0g 최적화를 적용하고 최적화 단계를 올리면 어떤 일이 생기는지 알아본다. 실제로는 더 높은 최적화가 프로그램 성능면에서 더 좋은 선택이다.
프로그램 컴파일과정
- GCC 명령은 소스 코드를 실행 코드로 변환하기 위해 일련의 프로그램들을 호출한다.
- C 전처리기가 #include로 명시된 파일을 코드에 삽입해주고, #define으로 선언된 매크로를 확장해 준다.
- 컴파일러가 두 개의 소스파일의 어셈블리 버전인 p1.s와 p2.s 를 생성한다.
- 어셈블러는 어셈블리 코드를 바이너리 목적 코드인 p1.o와 p2.o 으로 변환한다. ( 목적코드는 기계어 코드의 한 유형이고 모든 인스트럭션의 바이너리 표현을 포함하고 있으나 전역 값들의 주소는 아직 채워지지 않았다)
- 링커는 두 개의 목적코드 파일을 라이브러리 함수들을 구현한 코드와 함께 합쳐서 최종 실행파일인 p를 생성합니다.
실행 코드는 우리가 다루게 될 두 번째 형태의 기계어 코드다. 이것이 프로세서가 실행할 정확한 코드의 형태이다.
3-2-1 기계수준 코드
기계 수준 프로그래밍에서는
- 기계수준 프로그램의 형식과 동작은 이스트럭션 집합구조 ISA에 의해 정의된다. 이것은 프로세서의 상태, 인스트럭션 형식, 프로세서 상태에 대한 각 인스트럭션들의 영향들을 정의한다. x86-64를 포함함한 ISA는 하나의 인스트럭션이 다음 인스트럭션의 실행 전에 완료되는 순차적인 실행을 하는 것처럼 프로그램의 동작을 설명한다.
- 기계수준 프로그램이 사용하는 주소는 가상주소이며, 메모리가 매우 큰 바이트 배열인 것처럼 보이게 하는 메모리 모델을 제공합니다. 실제 메모리 시스템은 여러개의 메모리 하드웨어와 운영체제 소프트웨어로 구현되어 있다.
컴파일러는 전체 컴파일 순서에 C에서 제공하는 추상화 실행 모델로 표현된 프로그램을 프로세서가 실행하는 매우 기초적인 인스트럭션들로 변환하는 대부분의 일을 수행한다. 어셈블리 코드 표현은 바이너리 기계어 코드 형식과 비교할 때 더 읽기 쉬운 텍스트 형식이다.
x86-64를 위한 기계어 코드는 C코드와는 많이 다르다. 프로세서의 상태는 C 프로그래머에게는 감추어져 있다.
x86-64를 위한 기계어 코드 특징
- 프로그램 카운터(x86-64 기준 %rip)는 실행할 다음 인스트럭션의 메모리 주소를 가리킨다.
- 정수 레지스터 파일은 64비트 값을 저장하기 위한 16개의 이름을 붙인 위치를 갖고, 레지스터는 주소나 정수 데이터를 저장할 수 있다. 일부 레지스터는 프로그램의 중요한 상태를 추적하는데 사용할 수 있고, 다른 레지스터들은 함수 리턴 값만 아니라 프로시저의 지역변수와 인자 같은 임시 값을 저장하는데 사용한다.
- 조건 코드 레지스터들은 가장 최근에 실행한 산술/ 논리 인스트럭션에 관한 상태 정보를 저장한다. if나 while문을 구현 시 필요한 제어나 조건에 따른 데이터 흐름의 변경을 구현하기 위해 사용한다.
- 벡터 레지스터들의 집합은 하나 이상의 정수나 부동소수점 값들을 각각 저장할 수 있다.
추가적으로 CPU 명령어 집합 구조(ISA)를 설계하는 방식은 크게 RISC와 CISC으로 나눌 수 있습니다.
RISC의 특징과 장단점
(Reduced Instruction Set Computer)
특징
- 간단한 명령어 집합으로 구성됨 (명령어는 대부분 1 클럭 사이클로 수행)
- 명령어가 고정 길이로 되어 있어 디코딩이 쉬움
- 파이프라인 처리에 적합하여 고속 처리 가능
장점
- 처리 속도 빠름 (고속 연산 가능)
- 설계와 디버깅이 쉬움
- 전력 소비가 적어 모바일 기기에 적합
단점
- 복잡한 작업을 하려면 여러 명령어를 조합해야 함
- 코드 길이가 길어질 수 있음
CISC의 특징과 장단점
(Complex Instruction Set Computer)
특징
- 복잡하고 다양한 명령어를 지원 (1개 명령으로 여러 작업 가능)
- 명령어 길이가 가변적
- 하드웨어가 많은 기능을 내장
장점
- 한 명령어로 여러 작업을 처리할 수 있어 코드가 짧아짐
- 기존 소프트웨어와의 호환성 좋음
- 고급 언어에 가까운 명령어 제공
단점
- 명령어 해석이 복잡해 속도가 느릴 수 있음
- 하드웨어가 복잡하고 전력 소모가 큼
차이점 요약표
| 항목 | RISC (리스크) | CISC (시스크) |
|---|---|---|
| 명령어 수 | 적음 | 많음 |
| 명령어 복잡도 | 단순하고 짧음 | 복잡하고 다양한 형식 |
| 실행 속도 | 빠른 실행 (명령어당 클럭 수 적음) | 느릴 수 있음 (명령어당 클럭 수 많음) |
| 하드웨어 구조 | 간단한 설계 (제어 회로 간단) | 복잡한 설계 (제어 회로 복잡) |
| 대표 CPU | ARM, MIPS, SPARC | Intel x86, AMD |
| 상황 | 모바일, 임베디드 시스템 | 데스크탑, 서버, 호환성 중시 |
C는 다른 종류의 데이터 타입을 선언하고 메모리 할당할 수 있는 모델을 제공하고, 기계어 코드는 메모리를 단순히 바이트 주소지정이 가능한 큰 배열로 본다.
C에서는 배열과 구조체 같은 연결된 데이터 타입들은 기계어 코드에서 연속적인 바이트들로 표시된다. 스칼라 데이터 타입 경우에도 어셈블리 코드는 부호형과 비부호형, 다른 타입의 포인터들, 포인터, 정수형 사이도 구분하지 않는다.
프로그램 메모리는 실행 기계어 코드, 운영체제를 위한 일부 정보, 프로시저 호출과 리턴을 관리하는 런타임 스택, 사용자에 의해 할당된 메모리 블록들을 포함하고 있다. 언제나 가상주소의 일부 제한된 영역만이 유효하다.
운영체제는 이 가상 주소공간을 관리해서 가상주소를 관리해서 가상 주소를 실제 프로세서 메모리 상의 물리적 주소 값으로 번역해준다.
기계어 인스트럭션 하나는 매우 기초적인 동작만 수행한다. 예로, 레지스터들에 저장된 두 개의 수를 더하고, 메모리와 레지스터 간에 테이터를 교환하거나, 새로운 인스트럭션 주소로 조건에 따라 분기하는 등의 동작을 한다.
컴파일러는 일련의 인스트럭션을 생성해서 산술 연산식의 계산, 반복문 프로시저 호출과 리턴 등의 프로그램 구문을 구현해야 한다.
3-2-2 C코드를 어셈블리어로 변환하는 코드 예제
프로시저 정의를 포함하는 C 코드 파일을 mstore.c를 작성했다고 했을때,
long mult2(long, long);
void multstore(long x, long y, long *dest) {
long t = mult2(x, y);
*dest = t;
}C 컴파일러가 생성한 어셈블리 코드를 보기 위해 명령줄에서 -s 옵션을 사용할 수 있고, GCC로 컴파일러를 실행하도록 해서 어셈블리 파일 mstore.s를 만들고 더 이상 진행하지 않는다.
linux> gcc -Og -S mstore.c여기서 나온 mstore.s 파일은 다음과 같은 선언을 포함한다.
multstore:
pushq %rbx
//스택에 원래 %rbx값을 저장해둠
movq %rdx, %rbx
// %rdx에 저장된 dest값을 %rbx에 저장 (나중에 *dest = t할때 안전하게 사용하기 위해)
call mult2
//mult2(x,y) 호출
movq %rax, (%rbx)
// %rbx는 저장해둔 dest주소, %rax는 multi2(x,y) 결과 즉 *dest = result 값
popq %rbx
// 스택에서 %rbx값 꺼내서 복원
ret위 코드의 각 라인은 하나의 기계어 인스트럭션에 대응된다.
예시로 pushq 인스트럭션은 레지스터 %rbx가 프로그램 스택에 저장push 되어야 함을 의미한다.
변수 이름이나 데이터 타입에 관한 모든 정보는 삭제되었다.
명령어 라인 옵션을 사용하면 GCC는 코드를 컴파일하고 어셈블할 것이다.
linux> gcc -Og -c mstore.c바이너리 형식이어서 직접 볼 수 없는 목적코드 파일 mstore.o를 생성한다. 14바이트의 16진수 데이터가 mstore.o 파일에 1368바이트에 내장되있음을 알 수 있다.
→ 어떤 프로그램에 대한 이진 목적코드를 표시하기 위해서 역어셈블러를 사용하고 프로시저를 위한 코드가 14 바이트임을 알 수 있다. GNU 디버깅 도구 GDB를 mstore.o와 실행시키고 14개의 16진수 형태의 바이트들을 multstore 함수가 위치한 주소에서 시작하여 나태내라는 명령도 준다.(역어셈블을 하면 바이트수를 알 수 있다)
53 48 89 d3 e8 00 00 00 00 48 89 03 5b c3이건 위에 나열된 어셈블리 인스트럭션에 대응되는 목적코드이다. 이것으로 컴퓨터에 의해 실제 실행된 프로그램은 단순히 일련의 인스트럭션을 인코딩한 일련의 바이트임을 알 수 있다. 컴퓨터는 인스트럭션들이 생성된 소스 코드에 대한 정보를 거의 값고 있지 않다.(이걸 100퍼센트 역어셈블할 수 없다 오퍼레이션 코드)
역어셈블의 수행은 같은데 형태는 다를 수 있다. 즉, 위 이진 코드를 역어셈블하더라도 초기에 어셈블리어처럼 100퍼센트 같은 형태로 변환할 순 없다. 그러나 수행하는 역할은 같다.
기계어 코드 파일의 내용을 조사하려면, 역어셈블러라고 하는 프로그램이 중요하다. 프로그램들은 기계어 코드로부터 어셈블리어 코드와 유사한 형태를 생성한다. 리눅스 시스템에서 프로그램 objdump -d 커멘드를 사용하면 역할을 수행할 수 있다.
linux> objdump -d mstore.o바이너리코드(이진코드)를 역어셈블한 결과는(오른쪽)
0000000000000000 <multstore>: ; multstore 함수의 시작
오프셋: 바이너리 역 어셈블리어 결과
0: 53 push %rbx
; rbx 값을 스택에 저장 (함수 내에서 사용하므로 보존)
1: 48 89 d3 mov %rdx, %rbx
; 세 번째 인자 rdx (결과 저장 주소)를 rbx에 복사
4: e8 00 00 00 00 callq 9 <multstore+0x9>
; sum 함수 호출 (주소는 실제 실행 시 채워짐)
9: 48 89 03 mov %rax, (%rbx)
; sum의 반환값 rax를 rbx가 가리키는 주소에 저장
c: 5b pop %rbx
; 저장해두었던 rbx 값 복원
d: c3 retq
; 함수 종료 (복귀)왼쪽에는 앞에서 보았던 14개의 값을 볼 수 있고 역어셈블한 오른쪽 결과를 볼 수 있다. 이것은 각 1에서 5바이트 그룹으로 나누어져 있다. 위에서부터 각 그룹은 하나의 인스트럭션으로 오른쪽에 보여준 어셈블리어와 같다.
기계어 코드과 역어셈블된 표현은 다음과 같은 특징이있다.
x86-64 명령어 관련 설명
- 명령어 길이
- x86-64 명령어는 1바이트에서 최대 15바이트까지 길이가 다양함
- 자주 쓰이는 명령어일수록 짧게 인코딩됨, 드물고 복잡한 명령어는 더 길어짐
- 명령어 해석(디코딩)의 일관성
- 명령어 포맷이 고유하게 디코딩되도록 설계되어 있음.
(예: 바이트 값53으로 시작하는 명령어는 오직pushq %rbx하나뿐)
- 역어셈블러의 작동 방식
- 역어셈블러는 머신코드만 보고 어셈블리 코드로 바꿈
- 소스코드나 어셈블리 파일이 없어도 작동 가능
- 명령어 표기법 차이
- 역어셈블러는
gcc가 생성한 어셈블리 코드와 표기 방식이 조금 다름
(예: 디스어셈블러는 보통q접미사를 생략하지만,call이나ret에는 붙이기도 함) q는 크기(64비트)를 의미하며, 대부분의 경우 생략해도 무방함
- 바이너리의 오프셋
- 오프셋은 기준점으로부터의 상대적인 거리를 말함
- 쉽게, 시작점에서 얼마나 떨어져있는가를 의미
- 주로 메모리 주소, 바이너리 파일의 위치, 배열 인덱스 등에 사용
실제 실행 가능한 코드를 생성하기 위해, 링커를 목적코드들에 대해 실행해야하고, 이 중 한개의 파일은 main함수를 포함한다. main.c 파일에 다음과 같은 함수가 있다면,
#include <stdio.h>
void multstore(long, long, long *);
int main() {
long d;
multstore(2, 3, &d);
printf("2 * 3 –> %ld\n", d);
return 0;
}
long mult2(long a, long b) {
long s = a * b;
return s;
}실행 가능 프로그램인 prog를 다음과 같이 생성 가능하다.
linux> gcc -Og -o prog main.c mstore.c이렇게 생성하면 파일 크기가 8,655바이트로 늘어난다. 그 이유는 제공한 두 개의 프로시저뿐만 아니라 운영체제와 상호작용하기 위한 코드, 그리고 프로그램을 시작하고 종료하기 위한 코드들까지 포함하기 때문이다. 파일은 다음과 같이 역어셈블할 수 있다.
linux> objdump -d prog역어셈블러는 다음과 같이 여러가지 코드들을 추출한다.
Disassembly of function sum in binary file prog
1 0000000000400540 <multstore>:
2 400540: 53 push %rbx
3 400541: 48 89 d3 mov %rdx,%rbx
4 400544: e8 42 00 00 00 callq 40058b <mult2>
5 400549: 48 89 03 mov %rax,(%rbx)
6 40054c: 5b pop %rbx
7 40054d: c3 retq
8 40054e: 90 nop
9 40054f: 90 nop 해당 코드는 mstore.c를 역어셈블해서 생성한 것과 거의 동일하다.
중요한 차이점은 왼쪽에 나타낸 주소가 다르다는 것뿐, 링커가 이 코드의 위치를 다른 주소 영역으로 이동했다.
(주소는 바이너리 코드 왼쪽의 400540,400541 이런 것들이다)
두 번째 차이점은 링커가 callq인스트럭션이 함수 mult2를 호출할 때 사용해야하는 주소를 채웠다는 점이다.
(링커의 한 가지 임무는 이들 함수들을 위한 실행 코드의 위치들과 함수 호출을 일치시키는 것이다.)
마지막 차이는 두 줄의 추가된 라인을 볼 수 있는 것이다.
(인스트럭션은 이들이 7번줄의 리컨 인스트럭션 후에 발생하기 때문에 프로그램에는 아무 효과가 없을 것이다.
함수를 위한 코드 길이를 16바이트로 늘려서 코드의 다음 블록을 메모리 시스템 성능면에서 더 잘 배치하기 위해 삽입되었다.)
3-2-3 형식에 대한 설명
GCC가 생성하는 어셈블리 코드는 사람이 읽기가 어렵다. 한편으로는 우리가 걱정할 필요없는 정보를 포함하고 있으나 이건 프로그램이 어떻게 동작하고 정보에 대한 설명을 제공하지 않는다. 일례로, 다음 명령어를 실행하여 mstore.s를 생성한다.
linux> gcc -Og -S mstore.c해당 파일의 내용은
.file "010–mstore.c"
.text
.globl multstore
.type multstore, @function
multstore:
pushq %rbx
movq %rdx, %rbx
call mult2
movq %rax, (%rbx)
popq %rbx
ret
.size multstore, .–multstore
.ident "GCC: (Ubuntu 4.8.1–2ubuntu1~12.04) 4.8.1"
.section .note.GNU-stack,"",@progbits. 으로 시작하는 모든 라인은 어셈블러와 링커에 지시하기 위한 디렉티브들이다. 일반적으로 이들은 무시해도 된다. 반면, 인스트럭션들이 무엇을 하고, 이들이 어떻게 소스 코드와 연관되는지에 대한 설명이 없다.
어셈블리 코드를 보다 깔끔히 나타내기 위해 다부분의 디렉티브들은 생략하지만, 라인 번호와 설명하는 주석들은 포함 시키겠다.
1 multstore:
2 pushq %rbx ; %rbx 값을 스택에 저장 (보존을 위해)
3 movq %rdx, %rbx ; dest 포인터(%rdx)를 %rbx에 복사
4 call mult2 ; mult2 함수 호출 (x * y 수행)
5 movq %rax, (%rbx) ; 결과(%rax)를 dest가 가리키는 메모리에 저장
6 popq %rbx ; 이전에 저장한 %rbx 값을 복원
7 ret ; 호출한 함수로 복귀우린 일반적으로 논의하는 내용과 관련된 코드 부분만 나타낸다. 각 라인은 참조를 위해 왼쪽에 숫자를 표시하고, 오른쪽에는 각 인스트럭션의 효과와 그것이 어떻게 원본 C코드와 연관되는지 주석이 있다.
이것이 어셈블리어 프로그래머가 코드를 작성할 때 사용하는 정화된 버전이다. 그래서 이런식으로 표기를 하겠다.
[ATT와 인텔 어셈블리 코드 형식]
본문에서 어셈블리 코드, GCC, OBJDUMP를 ATT형식으로 나타낸다. 이러한 형식은 인텔 형식 어셈블리 코드와 다른 점이 있는데, GCC는 다음과 같은 명령어를 사용하면 multstore함수를 인텔 형식의 코드로 생성해준다.
linux> gcc -Og -S -masm=intel mstore.c이러면 어셈블리 코드를 만들어준다.
multstore:
push rbx
mov rbx, rdx
call mult2
mov QWORD PTR [rbx], rax
pop rbx
ret인텔과 ATT 형식은 다음과 같은 차이점
명령어 뒤에 붙는 접미사(suffix)가 없다
AT&T 문법에서는 명령어 뒤에q,l,w,b같은 접미사를 붙여서 데이터 크기를 표현해요.
예를 들어 64비트 데이터를 처리할 때는movq, 32비트는movl, 8비트는movb같은 식이에요.
그런데 Intel 문법은 그런 접미사를 생략합니다. 그냥mov,push이런 식으로만 써요.
→ 그래서movq대신mov,pushq대신push가 나오는 거죠.레지스터 이름 앞에
%기호를 안 붙인다
AT&T 문법에서는 레지스터 이름 앞에 항상%가 붙어요.
예:%rbx,%rax,%rdi같은 식이죠.
하지만 Intel 문법에서는%없이 그냥rbx,rax,rdi처럼 씁니다.
→%가 없으니 한결 간단해 보이지만, 두 문법을 섞어 보면 헷갈릴 수 있어요.메모리 주소를 표현하는 방식이 다르다
AT&T 문법에서는 메모리를 괄호()로 표현해요.
예:(%rbx)는 "rbx가 가리키는 메모리 주소"를 뜻합니다.
Intel 문법에서는 이걸[rbx]라고 쓰고, 자료 크기를 명확히 하기 위해BYTE PTR,QWORD PTR같은 키워드를 붙입니다.
예:QWORD PTR [rbx]→ "64비트 크기의 메모리 주소, rbx가 가리키는 곳"피연산자(operand) 순서가 반대다
가장 헷갈리는 부분이에요. AT&T 문법은 "원본 → 대상" 순서로 씁니다.
예:mov %rax, %rbx→ rax의 값을 rbx에 복사
하지만 Intel 문법은 "대상 ← 원본" 순서로 씁니다.
예:mov rbx, rax→ rax의 값을 rbx에 복사 (의미는 같지만 순서가 반대!)
→ 이 부분 때문에 두 문법을 오갈 때 혼동하기 쉬워요.
본문에서는 인텔 형식을 사용하지 않고 ATT형식으로 씁니다.
[웹 추가 정보 ASM:EASM] 어셈블리 코드를 C 프로그램과 함께 사용하기
C언어만으로 접근할 수 없는 하드웨어 수준 기능이 있다는 걸 설명하고 있다.
C언어는 우리가 많이 쓰는 고급 언어지만, 하드웨어의 모든 기능을 완전히 다룰 수없다. 컴파일러 가 대부분 잘 처리해주지만, CPU 내부에서 작동하는 아주 세세한 기능은 접근이 불가해 어셈블리 코드를 배워야한다.
예시로,
Parity Flag (pf)
pf는 x86-64 CPU에서 연산이 실행될 때 자동으로 설정되는 조건 플래그(Condition Code Flag) 중 하나입니다.pf는 결과값의 하위 8비트에 있는 1의 개수가 짝수이면 1로 설정되고, 홀수면 0으로 설정됩니다.
→ 그런데 문제는?
****이 값을 C 언어로 직접 확인할 수는 없습니다.
물론 C로 억지로 비슷한 결과를 계산할 수는 있어요.
하지만 그렇게 하려면 7번 이상 시프트, 마스크, XOR 같은 연산을 해야 해요. 비효율적입니다.
그러나 어셈블리 코드를 C프로그램에 일부 넣는다면 쉽게 해결됩니다.
- 전체 함수를 어셈블리 파일로 작성한 후 C 코드와 연결(link)
****.s 같은 어셈블리 소스 파일을 만들어 C 코드와 함께 컴파일합니다.
2. C 코드 안에 어셈블리 코드를 직접 삽입 (inline assembly)
C 코드 안에 어셈블리 코드를 asm 키워드로 삽입할 수 있습니다.
이런 방식으로, C만으로는 접근 못 하는 하드웨어 기능도 활용할 수 있게 되는 겁니다.
3.3 데이터의 형식
인텔은 16비트를 ‘워드’라고 하고 32비트는 ‘더블 워드’라고 한다. 64비트 양은 ‘쿼드 워드’라고 부른다.
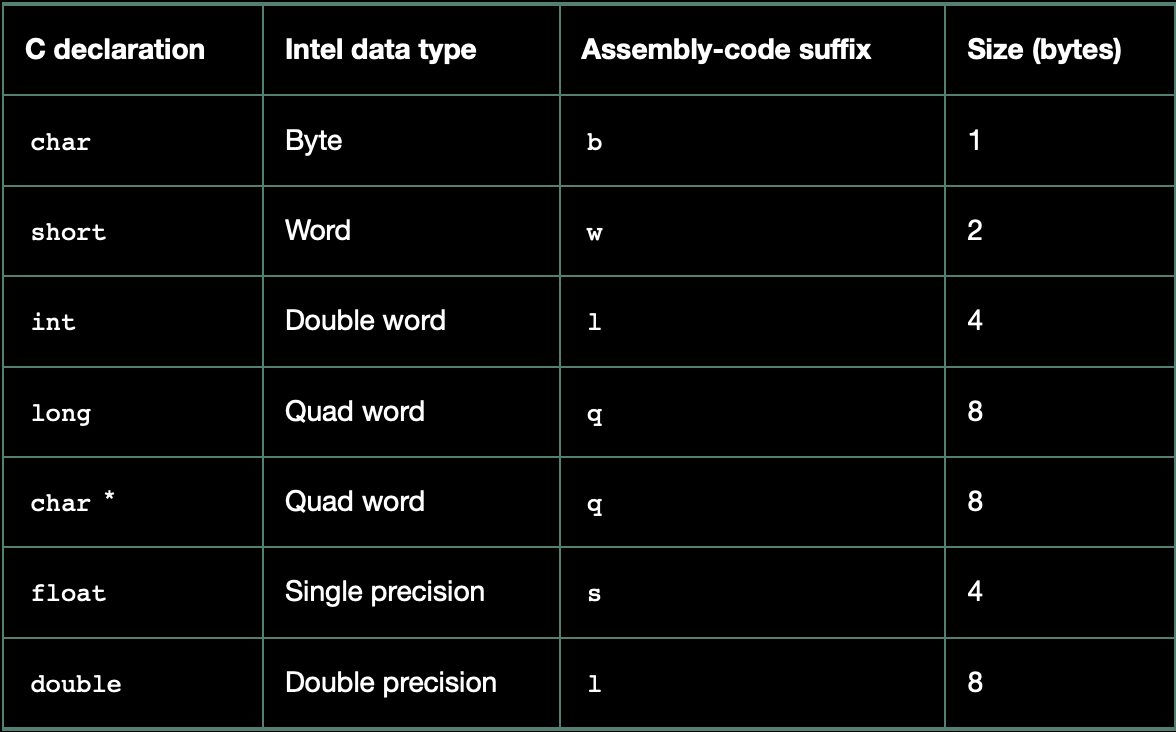
x86-64 시스템에서는 64비트 아키텍처이기 때문에 포인터는 8바이트(64비트) 크기를 가지며, 대부분의 연산이 8바이트 단위인 쿼드 워드(quad word)로 처리됩니다. 물론 명령어 집합에는 1바이트(byte), 2바이트(word), 4바이트(double word)를 위한 명령어도 모두 포함되어 있어 다양한 크기의 데이터 조작이 가능합니다. 부동소수점 숫자는 주로 두 가지 형식으로 나타나는데, 4바이트 크기의 단정도(single-precision)는 C의 float 타입에, 8바이트 크기의 배정도(double-precision)는 double 타입에 해당합니다. x86 계열의 마이크로프로세서들은 과거에 10바이트(80비트) 크기의 특수한 부동소수점 형식을 사용했으며, 이는 C에서 long double로 지정할 수 있습니다. 하지만 이 형식은 다른 플랫폼에서는 호환되지 않고, 대부분의 경우 고성능 하드웨어로 지원되지 않기 때문에 사용을 권장하지 않습니다.
또한 gcc가 생성하는 어셈블리 코드에서는 피연산자의 크기를 나타내는 한 글자짜리 접미사를 명령어 뒤에 붙입니다. 예를 들어 데이터 이동 명령어인 mov는 크기에 따라 movb(1바이트), movw(2바이트), movl(4바이트), movq(8바이트)로 구분됩니다. 여기서 l 접미사는 4바이트 크기의 정수를 뜻하는데, 이는 32비트 데이터가 "long word"로 간주되기 때문입니다. 또한 8바이트 크기의 double형 실수도 어셈블리 코드상에서는 l 접미사를 통해 표현되지만, 실수 연산은 별도의 명령어 집합과 레지스터를 사용하므로 혼동될 일은 없습니다.
'크래프톤 정글(알고리즘 주차 WEEK 0 ~ 4)' 카테고리의 다른 글
| 플로이드 와샬 알고리즘 (0) | 2025.04.11 |
|---|---|
| WEEK 04 알고리즘 TIL(4월7일 월요일) (0) | 2025.04.11 |
| WEEK 04 여담(4월6일 일요일) (0) | 2025.04.11 |
| WEEK 04 알고리즘 TIL(4월5일 토요일) (0) | 2025.04.11 |
| LCS (0) | 2025.04.11 |