## **3.4 정보 접근하기**
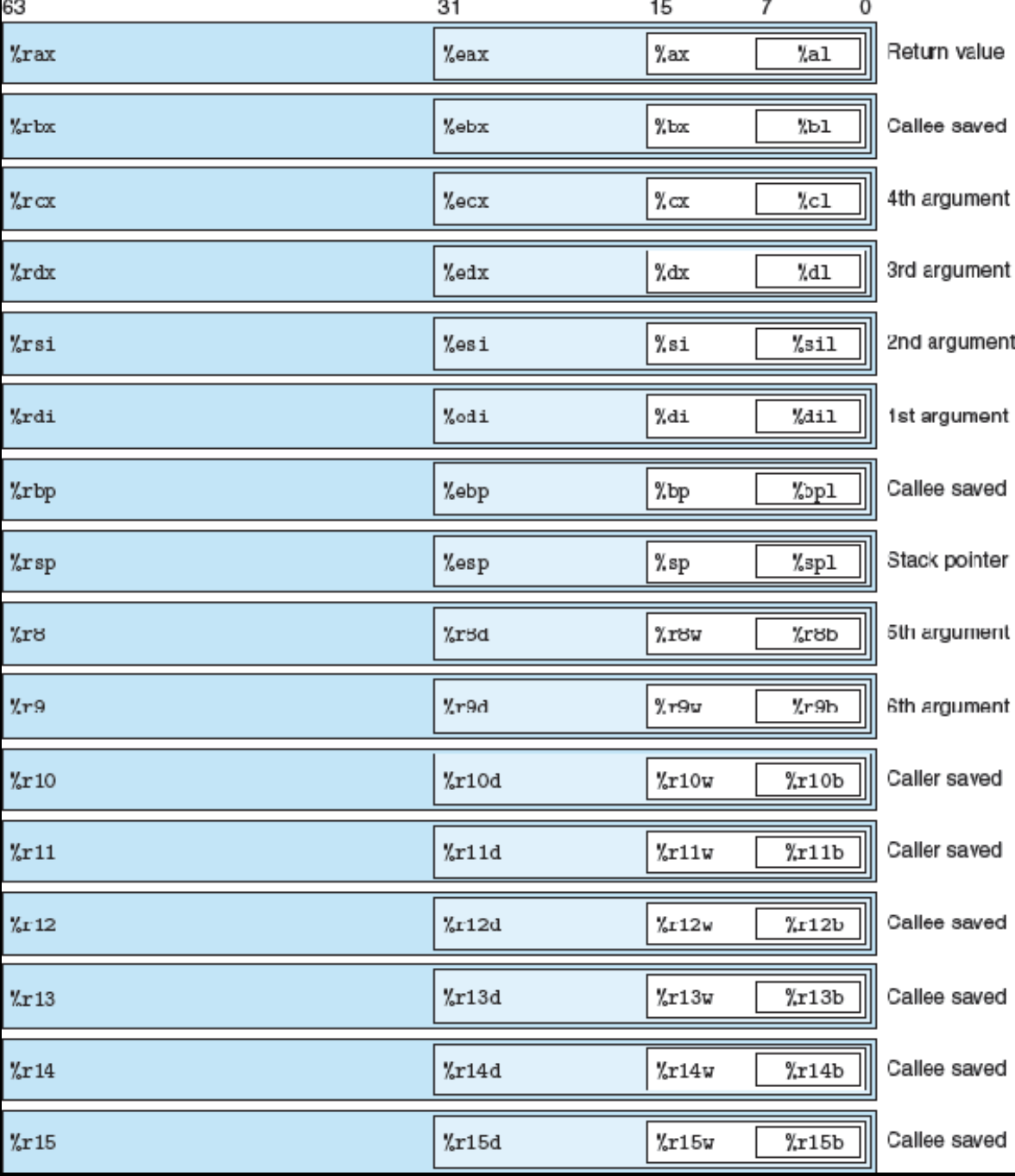
x86-64 프로세서는 64비트 값을 저장할 수 있는 16개의 범용 레지스터(general-purpose register)를 가지고 있습니다. 이 레지스터들은 정수 데이터와 포인터를 저장하는 데 사용되며, 모두 `%r`로 시작하는 이름을 가지고 있지만, 역사적인 발전 과정에 따라 다양한 명명 규칙이 섞여 있습니다. 초기 8086 프로세서에는 16비트 크기의 8개 레지스터가 있었고, 각각 `%ax`, `%bx`, `%cx`, `%dx` 등의 이름을 가졌습니다. 이들은 각기 고유한 용도에 따라 이름이 정해졌습니다. 이후 IA32(32비트 아키텍처)로 확장되면서 이 레지스터들은 32비트로 늘어나며 `%eax`, `%ebx` 같은 이름으로 바뀌었고, x86-64 아키텍처에서는 이들이 다시 64비트로 확장되어 `%rax`, `%rbx` 등으로 사용됩니다. 여기에 더해 새롭게 8개의 64비트 레지스터가 추가되었는데, 이들은 `%r8`부터 `%r15`까지 새로운 규칙에 따라 명명되었습니다.
이 레지스터들은 하나의 64비트 전체 값뿐 아니라, 그 하위 일부만을 사용해 연산할 수도 있습니다. 예를 들어, 바이트(1바이트), 워드(2바이트), 더블 워드(4바이트), 쿼드 워드(8바이트) 단위로 각각 하위 바이트에 접근할 수 있는 구조입니다. 이런 구조 덕분에 하나의 레지스터를 다양한 크기의 연산에 유연하게 사용할 수 있습니다. 예를 들어 `movb`, `movw`, `movl`, `movq` 같은 명령어들이 각각 1, 2, 4, 8바이트 크기의 데이터를 다룰 수 있는 이유입니다. 쪼개는 이유는 메모리를 아끼고 속도를 최적화하며, 레거시 코드와 호환하기 위함입니다.
이와 관련하여 중요한 동작 규칙도 있습니다. 어떤 명령어가 1바이트나 2바이트 크기의 데이터를 레지스터에 저장할 경우, 해당 레지스터의 나머지 상위 바이트들은 그대로 유지됩니다. 하지만 4바이트 크기의 값을 저장할 경우에는 상위 4바이트가 자동으로 0으로 초기화됩니다. 이 규칙은 32비트에서 64비트로 확장되며 도입된 것으로, 레지스터 초기화와 관련된 오류를 줄이는 데 도움이 됩니다.
16개의 레지스터 중에서도 `%rsp`는 특별한 역할을 합니다. 이 레지스터는 스택 포인터로 사용되며, 현재 스택의 끝 지점을 가리킵니다. 일부 명령어는 이 레지스터를 직접 읽거나 쓸 수 있으며, 함수 호출과 반환, 지역 변수 관리에 핵심적인 역할을 합니다. 나머지 레지스터들은 상대적으로 더 자유롭게 사용할 수 있지만, 함수 인자 전달, 반환값 저장, 임시 데이터 보관 등의 목적에 따라 표준적인 사용 규약이 정해져 있습니다. 이 규약들은 특히 함수 호출 구현과 관련된 내용에서 중요한데, 이후 학습에서 자세히 다루게 될 것입니다.
## **3.4.1 오퍼랜드 식별자**
x86-64 어셈블리 언어에서 대부분의 명령어는 연산에 사용될 값(소스)과 그 결과를 저장할 위치(목적지)를 명시하는 오퍼랜드(operand)를 포함합니다. 이 오퍼랜드는 즉시값(상수), 레지스터 값, 메모리 참조의 세 가지 형태로 나뉩니다.

첫 번째는 즉시값(immediate)으로, 단순한 상수값을 의미합니다. AT&T 어셈블리 문법에서는 `$` 기호 다음에 정수를 써서 표현하며, 예를 들어 `$-577` 또는 `$0x1F`처럼 쓸 수 있습니다. 명령어마다 허용되는 상수의 범위는 다르며, 어셈블러는 주어진 값을 가장 효율적으로 인코딩할 수 있는 방법을 자동으로 선택해 줍니다.
ex) movq $5, %rax , ← 숫자 5를 바로 `%rax`로 넣음
두 번째는 레지스터(register) 오퍼랜드입니다. 이는 현재 CPU가 갖고 있는 16개의 범용 레지스터 중 하나를 사용해 값을 읽거나 저장하는 방식입니다. 명령어가 처리하는 데이터 크기에 따라 64비트, 32비트, 16비트, 8비트 등 다양한 크기의 레지스터 하위 부분이 사용됩니다. 예를 들어 64비트 연산은 `%rax` 같은 전체 레지스터를, 8비트 연산은 `%al` 같은 하위 바이트만 사용합니다.
**ex**) addq %rbx, %rax ← `%rbx`를 `%rax`에 더함
세 번째는 가장 복잡하지만 강력한 메모리 참조(memory reference) 형태입니다. 이는 메모리 주소를 계산하여 특정 위치에 접근하는 방식인데, 이를 유효 주소(effective address)라 부릅니다. 메모리를 바이트 배열처럼 본다면, 예를 들어 `M[Addr]`은 Addr 주소에서 시작하는 값을 의미합니다.
메모리 참조에는 다양한 주소 지정 방식(addressing modes)이 존재합니다. 그중 가장 일반적인 형식은 다음과 같습니다(상단 표 마지막 Form):
```
Imm(rb, ri, s)
```
여기서 각 구성요소는 다음과 같습니다:
- `Imm`: 상수 오프셋(예: 8, -4 등)
- `rb`: 기준(base) 레지스터
- `ri`: 인덱스(index) 레지스터
- `s`: 스케일(배율) 인자 (1, 2, 4, 8 중 하나)
이 유효 주소는 다음과 같은 수식으로 계산됩니다:
```
유효주소 = Imm + R[rb] + R[ri] * s
```
이 방식은 특히 배열이나 구조체 요소에 접근할 때 자주 사용됩니다. 예를 들어 배열의 i번째 요소에 접근하려면, 배열 시작 주소(base)에 인덱스(index)와 크기(scale)를 곱한 값을 더해서 접근합니다. 이처럼 복잡한 메모리 참조는 코드의 유연성과 성능을 크게 높여줍니다. 간단한 메모리 참조 형식들은 이 일반형에서 일부 요소가 생략된 특별한 경우에 해당합니다.
### **오버랜드 식별자 해설**
1. Immediate
Form : `$Imm`
Operand Value : `Imm` (즉 상수 그자체)
2. Register
Form : `%rax`
Operand Value : 해당 레지스터의 값
3. Memory (Absolute)
Form : `Imm`
Operand Value : 메모리의 Imm 주소에 저장된 값
4. Memory (Indirect)
Form : `(%rax)`
Operand Value : `$rax`가 가리키는 주소의 값
5. Base + Displacement
Form : `8(%rax)`
Operand Value : `8` + `%rax` 주소에 있는 메모리 값
6. Indexed
Form : `(%rbx, %rcx)`
Operand Value : `%rbx` + `%rcx` = 주소
7. Indexed with Displacement
Form : `16(%rbx, %rcx)`
Operand Value : 16 + `%rbx` + `%rcx` = 주소
8. Scaled Indexed
Form : `(,%rsi,4)`
Operand Value : `%rsi * 4` = 주소
배열 인덱스 접근시에 유용함
9. Scaled Indexed with Displacement
Form : `8(, %rsi, 4)`
Operand Value : 8 + %rsi * 4
10. Base + Scaled Index
Form : `(%rbx, %rcx, 8)`
Operand Value : %rbx + %rcx * 8
곱하기는 무조건 인덱스 레지스터 하나에만 사용됨
11. Base + Index + Displacement + Scale
Form : `32(%rdi, %rsi, 4)`
Operand Value : 32 + `%rdi` + `%rsi` * 4
## **3.4.2 데이터 이동 인스트럭션**
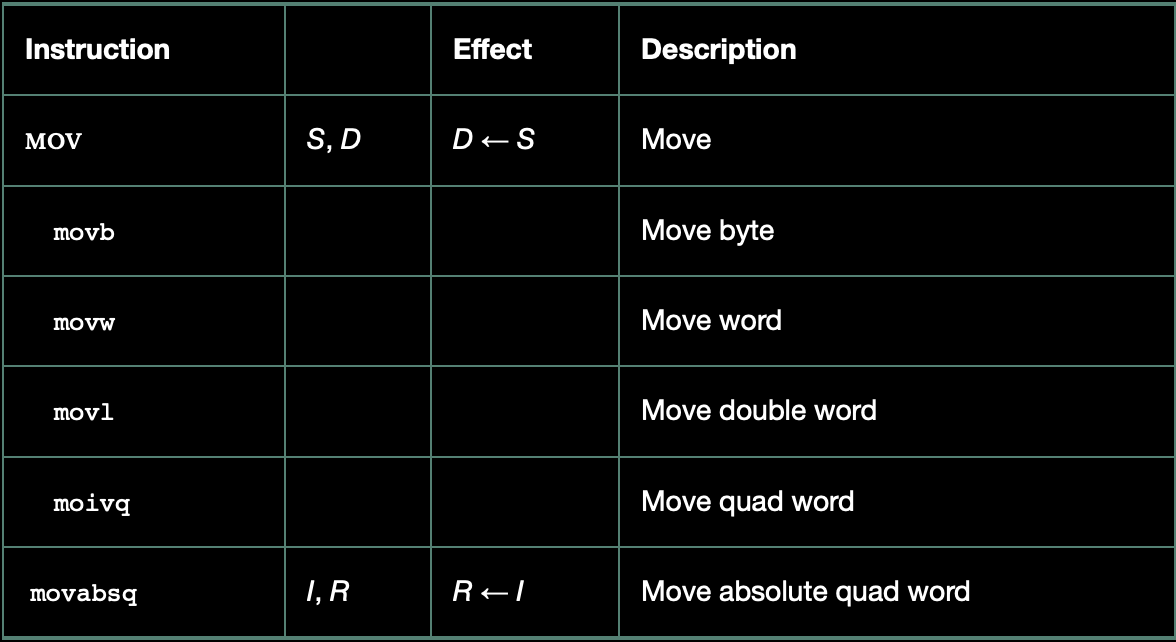
x86-64 어셈블리 언어에서 가장 자주 사용되는 명령어 중 하나는 **데이터를 복사하는 명령어**입니다. 이 명령어들은 한 위치에서 다른 위치로 값을 그대로 옮기는 역할을 합니다. x86-64는 오퍼랜드 표기법이 매우 유연해서, 아주 간단한 명령어 한 줄로도 다양한 상황에서 데이터를 복사할 수 있습니다. 어떤 다른 컴퓨터 구조에서는 여러 개의 다른 명령어가 필요한 작업도, 여기서는 하나의 mov 명령어로 해결할 수 있는 경우가 많습니다.
이 데이터 복사 명령어들은 여러 가지 버전이 있으며, 각각 **복사하는 데이터의 크기**에 따라 다르게 사용됩니다. 이 명령어들은 movb, movw, movl, movq 네 가지로 나뉘는데, 접미사에 따라 다음과 같은 크기의 데이터를 다룹니다:
- **movb**: 1바이트 (byte)
- **movw**: 2바이트 (word)
- **movl**: 4바이트 (double word)
- **movq**: 8바이트 (quad word)
이 네 가지 명령어는 모두 기본적으로 같은 일을 합니다. 바로 **소스에서 데이터를 읽어서, 변형 없이 목적지에 그대로 저장**하는 것입니다. 단지 처리하는 데이터의 크기만 다를 뿐이죠. 예를 들어, `movq`는 8바이트 데이터를 옮길 때 사용하고, `movb`는 1바이트만 복사할 때 사용됩니다.
이렇게 간단하면서도 강력한 mov 명령어 덕분에, 복잡한 연산 없이도 다양한 방식으로 데이터를 효과적으로 옮길 수 있습니다. 이러한 mov 명령어는 어셈블리 코드를 이해하고 작성하는 데 있어 가장 기본이 되는 개념이기도 합니다.
x86-64 어셈블리에서 `mov` 명령어는 데이터를 복사할 때 자주 사용됩니다. 이 명령어에는 두 개의 오퍼랜드(피연산자)가 필요합니다. 첫 번째는 소스(원본)이며, 두 번째는 목적지(저장할 위치)입니다.
소스는 상수 값(즉시값), 레지스터, 또는 메모리의 값일 수 있고, 목적지는 레지스터나 메모리의 주소가 될 수 있습니다. 하지만 중요한 제한이 하나 있습니다: 소스와 목적지 둘 다 메모리일 수는 없습니다. 즉, 메모리에서 메모리로 직접 복사하는 mov 명령어는 존재하지 않습니다.
따라서 메모리에서 메모리로 값을 옮기려면 반드시 중간에 레지스터를 거쳐야 합니다.
예를 들면 이렇게 두 단계로 진행됩니다(인스트럭션도 필요):
1. 메모리에서 값을 읽어 레지스터에 저장(소스값을 레지스터 적재하는 인스트럭션)
2. 그 레지스터 값을 다시 다른 메모리 위치에 저장(레지스터의 값을 목적지에 쓰기 위한 인스트럭션)
또한 `mov` 명령어는 접미사에 따라 복사할 데이터의 크기를 결정합니다.
b: 1바이트, w: 2바이트, l: 4바이트, q: 8바이트
이 접미사는 명령어가 동작하는 **레지스터나 메모리의 크기**를 알려주며, 반드시 크기에 맞는 레지스터나 메모리 영역에 사용해야 합니다. 예를 들어 `movb`는 1바이트 레지스터나 메모리에만 사용할 수 있습니다.
일반적으로 `mov` 명령어는 지정된 위치에만 영향을 주는데, **예외**가 하나 있습니다.
- `movl` 명령어가 레지스터를 목적지로 사용할 때, 해당 레지스터의 상위 4바이트가 자동으로 0으로 초기화됩니다.
이는 x86-64에서 32비트 값을 생성하는 명령어는 항상 상위 32비트를 0으로 만든다는 규칙 때문입니다.
```nasm
1 movl $0x4050,%eax Immediate--Register, 4 bytes
2 movw %bp,%sp Register--Register, 2 bytes
3 movb (%rdi,%rcx),%al Memory--Register, 1 byte
4 movb $-17,( %esp) Immediate--Memory, 1 byte
5 movq %rax,–12(%rbp) Register--Memory, 8 bytes
```
추가적인 명령어: `movabsq` (64비트 즉시값 처리)
보통 `movq` 명령어는 64비트 레지스터에 값을 복사할 때 사용되지만, 즉시값(상수)으로는 32비트 범위 안의 값만 사용할 수 있습니다. 이 값은 부호 확장을 통해 64비트로 바뀝니다.
그런데 어떤 경우에는 진짜 64비트 값 전체를 즉시값으로 넣고 싶을 때가 있습니다. 이럴 때 사용하는 특별한 명령어가 `movabsq`입니다. 이 명령어는 64비트 즉시값 전체를 복사할 수 있지만, 목적지는 반드시 레지스터여야 합니다.
또한 이후 이어지는 `movz`나 `movs`와 같은 명령어들은 작은 크기의 값을 더 큰 레지스터로 옮길 때 사용되며, 이 때는 제로 확장(zero extension) 또는 부호 확장(sign extension)이 일어나는 특징이 있습니다. 이는 나중에 배열이나 구조체를 다룰 때 매우 유용하게 사용됩니다.
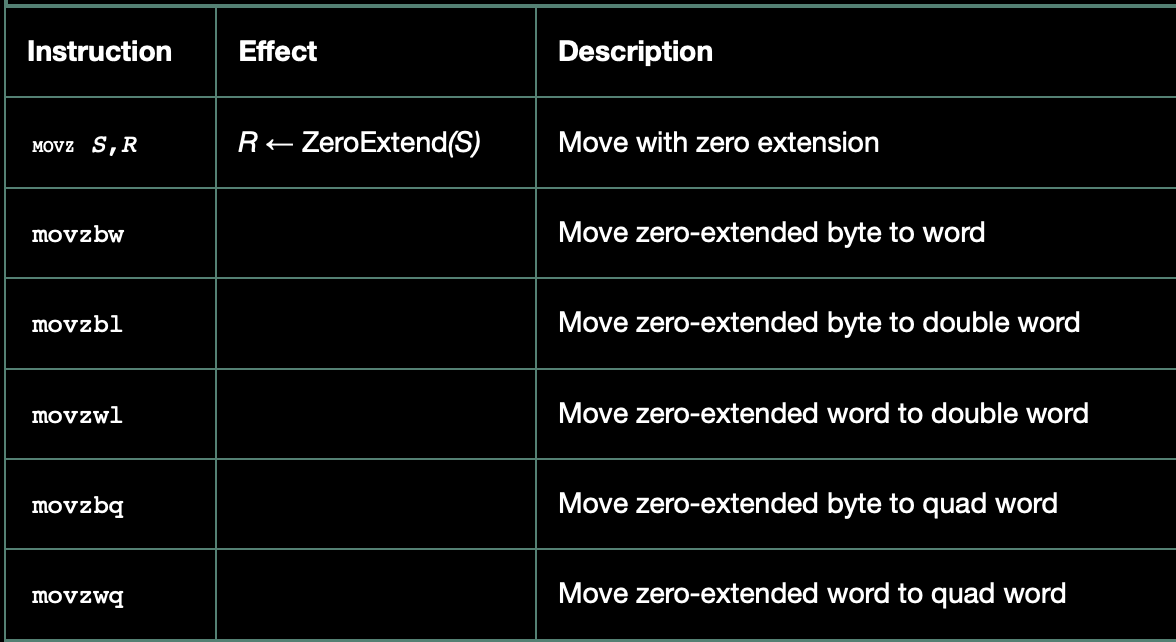
- `movz` 클래스: 남는 바이트를 0으로 채움 (제로 확장)
- `movs` 클래스: 남는 바이트를 부호 확장, 즉 원본의 최상위 비트를 복사해서 채움
각 클래스는 1바이트와 2바이트를 소스로, 2바이트와 4바이트를 목적지로 하는 경우에 대해 총 **3개의 조합**이 정의되어 있습니다. 단, **작은 크기에서 큰 크기로 옮기는 경우만**을 다루며, 같은 크기거나 줄이는 경우는 포함되지 않습니다.
흥미롭게도, 4바이트 값을 8바이트 레지스터로 **제로 확장**하는 전용 명령어는 존재하지 않습니다. 논리적으로는 `movzlq`라는 명령어가 있어야 할 것 같지만, 실제로는 이런 명령어가 없습니다. 대신에 단순히 `movl` 명령어를 사용하면, 목적지가 레지스터일 때 자동으로 상위 4바이트가 0으로 채워지므로 제로 확장과 동일한 효과를 얻을 수 있습니다. 이는 x86-64 아키텍처의 설계상 특징 중 하나입니다.
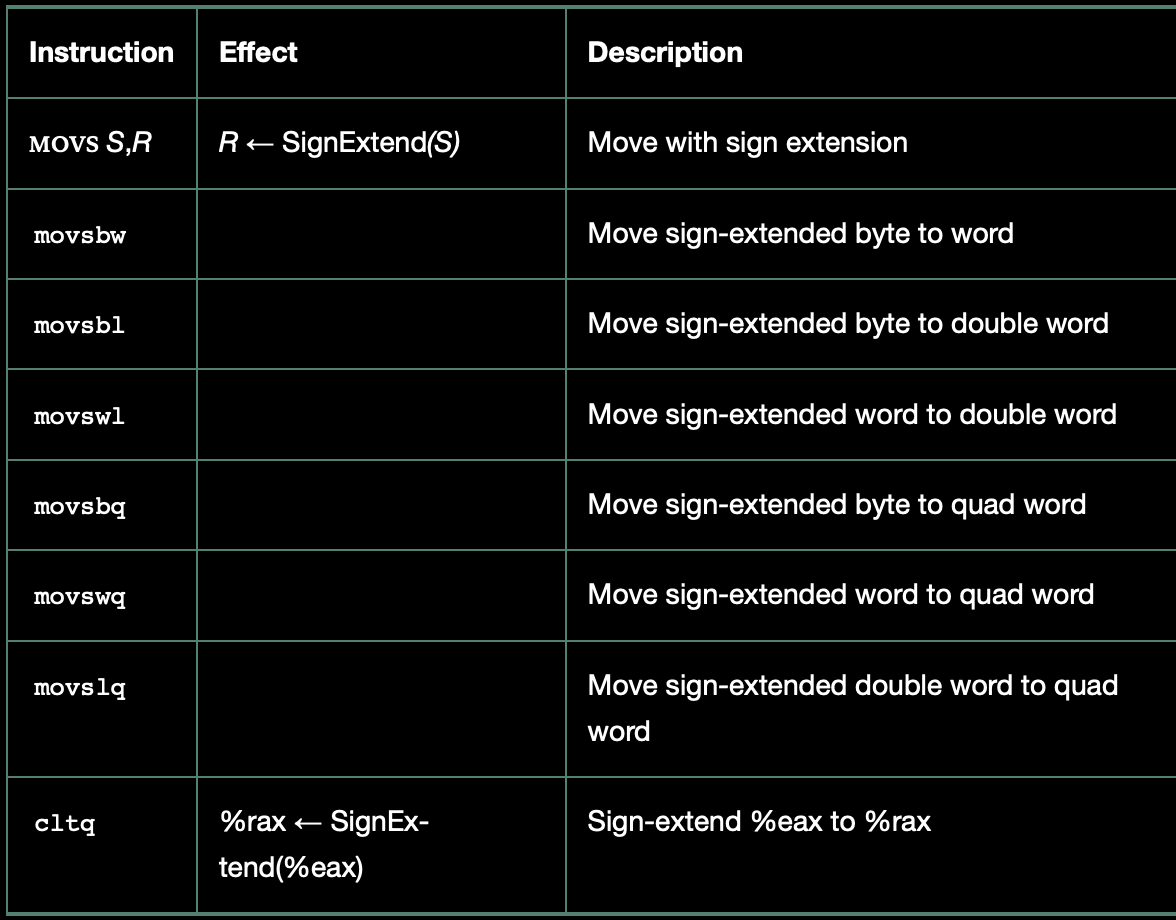
`movs` 명령어는 부호 확장(sign extension)을 수행합니다. 이때도 소스는 레지스터 또는 메모리일 수 있고, 목적지는 반드시 레지스터입니다. `movsbw`, `movswl`, `movsbq` 등 다양한 변형이 있으며, 각 변형은 원본 크기와 목적지 크기에 따라 결정됩니다.
여기서 특별한 명령어로 `cltq`가 있는데, 이 명령어는 오퍼랜드 없이 **무조건 `%eax`를 소스로, `%rax`를 목적지로** 사용합니다. `%eax`의 32비트 값을 부호 확장하여 64비트 `%rax`에 저장하는 역할을 하며, 실제로는 `movslq %eax, %rax`와 같은 효과를 갖지만 **인코딩이 더 짧고 효율적**입니다.
또한, 많은 사람들이 궁금해할 수 있는 점 하나는 4바이트 값을 8바이트 레지스터로 제로 확장하는 명령어가 왜 없느냐입니다. 논리적으로 보면 `movzlq`라는 이름이 있을 법하지만, 실제로는 존재하지 않습니다. 대신 `movl` 명령어를 사용하면 동일한 효과를 얻을 수 있습니다. 이유는 간단한데, `movl` 명령어는 목적지가 레지스터일 경우 자동으로 상위 4바이트를 0으로 초기화해주기 때문입니다. 이 규칙을 활용하면 굳이 `movzlq`가 없어도 제로 확장 효과를 얻을 수 있습니다.
> [추가정보] 데이터 이동이 목적지 레지스터를 변경하는 방법
앞에서 설명한 것처럼 데이터 이동 인스트럭션이 목적지 레지스터의 상위 바이트를 변경하는지와 어떻게 변경하는지는 두 가지 방식이 있다.
>
```nasm
1 movabsq $0x0011223344556677, %rax %rax = 0011223344556677
2 movb $-1, %al %rax = 00112233445566FF
3 movw $-1, %ax %rax = 001122334455FFFF
4 movl $-1, %eax %rax = 00000000FFFFFFFF
5 movq $-1, %rax %rax = FFFFFFFFFFFFFFFF
```
> 앞으로 16진수 표기를 사용한다. 해당 예제에서 1번 줄의 인스트럭션은 레이스터 %rax를 패턴 0011223344556677로 초기화 한다. 나머지 이스트럭션들은 즉시값 -1을 소스 값으로 가진다. -1의 16 진수 표시는 FFFFFF…FF 형태를 가지고 F의 개수는 표시하는 바이트 수의 두 배이다. 따라서 movb 인스트럭션은 %rax의 하위바이트를 FF로 설정하기만, movw 인스트럭션은 하위 2바이트를 FFFF로 설정하며, 다른 바이트들은 그대로 둔다. movl 인스트럭션은 하위 4바이트를 FFFFFFFF로 설정하지만, 이것도 상위 바이트를 0000000으로 설정한다. 마지막으로 movq 인스트럭션은 레지스터 전체를 FFFFFFFFFFFFFF로 설정한다.
>
> [추가정보] 바이트 이동 인스트럭션
이 예제는 어떻게 데이터 이동 인스트럭션들이 목적지의 상위 바이트들을 변경하는지, 안하는지를 보여준다. 세 개의 바이트 이동 인스트럭션(movb, movsbq, movzbq)는 서로 미세한 차이점을 갖는다는 점에 주목해야한다.
>
```nasm
1 movabsq $0x0011223344556677, %rax %rax = 0011223344556677
2 movb $0xAA, %dl %dl = AA
3 movb %dl,%al %rax = 00112233445566AA
4 movsbq %dl,%rax %rax = FFFFFFFFFFFFFFAA
5 movzbq %dl,%rax %rax = 00000000000000AA
```
> 모든 값에 대해서 16진수 표시를 이용한다.
코드의 첫 두 줄은 레지스터 %rax, %dl을 00112233445566AA과 AA로 초기화한다. 나머지 인스트럭션들은 모두 %rdx의 하위 바이트를 %rax의 하위 바이트로 복사한다.
movb인스트럭션은 다른 바이트들을 변경하지 않음.
movsbq인스트럭션은 다른 7바이트를 소스 바이트의 상위 비트에 따라 1 또는 0으로 설정한다. 6진수 A가 이진수 1010을 나타내, 부호 확장을 하면 상위 바이트 들을 각각 FF로 세팅한다.
movzbq 인스트럭션은 항상 다른 7바이트를 0으로 설정한다.
>
## **3.4.3 데이터 이동 예제**
C code
```c
long exchange(long *xp, long y)
{
long x = *xp;
*xp = y;
return x;
}
```
Assembly code
```nasm
long exchange(long *xp, long y)
xp in %rdi, y in %rsi
1 exchange:
2 movq (%rdi), %rax xp에서 x를 가져옵니다. 반환 값으로 설정합니다.
3 movq %rsi, (%rdi) y를 xp로 저장합니다.
4 ret Return.
```
함수 exchange는 단 세 개의 인스트럭션으로 구현되었다.
2개의 데이터 이동 movq / 함수가 호출된 위치로 리턴하는 인스트럭션 1개 ret.
함수의 호출과 리턴은 3.7에서 나온다. 그 전까지 그냥 인자들이 레지스터로 함수에 전달된다고 알면된다.
상단의 어셈블리 코드는 리턴 값을 레지스터 %rax에 저장해서 함수가 값을 리턴하거나, 이 레지스터의 하위 부분 중의 하나로 리턴한다.
프로시저가 실행시, 프로시저 매개변수 xp와 y는 레지스터 %rdi와 %rsi에 저장된다.
2번 줄은 x를 메모리에서 읽어서 레지스터 %rax에 저장하며, 이것은 C프로그램에서 x = *xp로 직접 구현된다. 나중에 레지스터 %rax는 함수 값을 리턴시 사용한다. 그래서 리턴 값이 x이다.
3번 줄은 y를 레지스터 %rdi에 저장된 xp로 지정한 메모리 위치에 써주고, 이것은 연산 *xp = y 를 직접 구현한 것이다. 이 예제는 어떻게 MOV 인스트럭션을 이용해서 메모리에서 레지스터로 읽어들이는지, 레지스터에서 메모리로 쓰는지를 보여준다.
이 어셈블리 코드에서 두 가지 특징에 주목할 필요가 있다.
1. C언어에서 “포인터”라고 부르는 것이 어셈블리어에서는 단순히 주소다.
포인터를 역참조하는 것은 포인터를 레지스터에 복사하고, 이 레지스터를 메모리 참조에 사용하는 과정으로 이루어진다.
2. x 같은 지역변수들은 메모리에 저장되기보다는 종종 레지스터에 저장된다는 점이다. 레지스터의 접근은 메모리보다 속도가 훨씬 빠르다.
> **[C언어] 포인터 예제**
함수 exchange는 C에서 포인터 사용을 잘 보여준다. 인자 xp는 long int의 포인터이고, y는 long integer이다. 다음 문장은 xp로 표시되는 위치에 저장된 값을 읽어서 지역변수 x에 저장함을 의미한다.
long x = *xp
이와 같이 C연사자 *은 포인터 역참조를 실행한다. 정반대의 연산을 수행한다. 매개변수 y의 값을 xp가 지정하는 위치에 쓴다.
*xp = y;
이것도 또 다른 형태인데, 할당문의 좌변에 위치하므로 쓰기 연산 포인터 역참조를 의미한다.
long a = 4;
long b = exchange(&a, 3);
printf(”a = %ld, b = %ld\n”, a, b);
→ a = 3, b = 4
C 연산자 &는 포인터를 만들어 주며, 이 예제에서는 지역변수 a를 저장하고 있는 위치의 주소를 생성한다. 함수 exchange는 a에 저장되어 있던 값을 3으로 덮어쓰지만, 함수값으로 이전 값인 4를 리턴한다.
>
→ 포인터는 변수의 중복된 사본을 메모리에 복사함으로써 낭비될 수 있는 자원을 주소를 통해 직접 참조를 할 수 있게끔 하므로써 메모리 낭비를 줄인다.(주소를 지정할 때 자료형 등을 추가해 종료되는 지점도 추가한다)
## 3.4.4 스택 데이터의 저장과 추출
두 개의 데이터 이동 연산은 프로그램 스택에 데이터를 저장push 하거나 스택에서 데이터를 추출pop하기 위해 사용한다. 스택은 프로시저 호출을 처리하는데 중요한 역할을 한다. 우리가 알다시피, 스택은 후입선출(나중에 들어온것이 첫번째로 출력)이다. push연산으로 스택에 데이터를 추가하고 pop연산으로 제거하되, 제거하는 값이 가장 최근에 추가된 값이고 스택에 남아있다. 스택은 배열로 구현되고, 배열에서 원소들을 배열의 한쪽 끝에서만 추가하거나 제거한다. 끝부분은 top이라 한다. x86-64에서 프로그램 스택은 메모리 특정 영역에 위치한다.
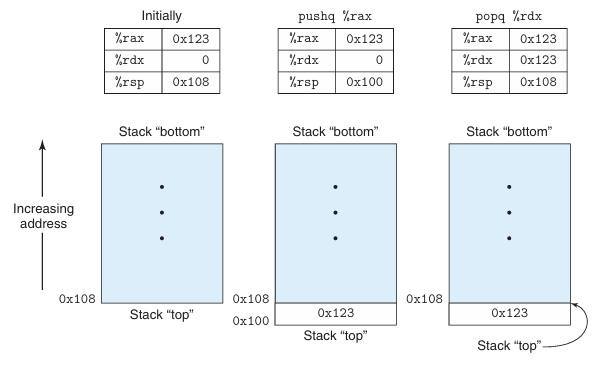
위처럼 스택의 탑 원소가 모든 스택 원소 중에서 가장 낮은 주소를 갖고, 스택은 아래 방향으로 성장한다.(관습상 위아래가 바뀐 그림을 그린다고한다) 스택 포인터 %rsp는 스택 맨 위 원소의 주소를 저장한다.
popq는 데이터를 추출하고 pushq는 데이터를 스택에 추가한다. 이 인스트럭션은 한 개의 오퍼랜드를 사용한다. (추가할 소스 데이터와 추출을 위한 데이터 목적지까지)
### **스택에서의 pushq**
쿼드워드 값을 스택에 추가하려면, 먼저 스택 포인터를 8 감소시키고, 그 값을 스택 주소의 새로운 탑에 기록하는 것으로 구현된다. 그래서 pushq %rbp 동작은 다음과 같은 인스트럭션과 같다.
```nasm
subq $8,%rsp 스택 포인터 감소
movq %rbp,( %rsp) 스택에 %rbp 저장
```
위 두 개의 인스트럭션은 총 8바이트가 필요하지만, pushq는 한 바이트의 기계어 코드로 인코딩된다는 차이가 있다. 첫 두 열은 %rsp가 0x108이고 pushq %rax를 실행한 결과를 보여준다. %rsp는 8 감소해서 0x100이되고, 0x123이 메모리 주소 0x100에 저장된다.
---
### **스택에서의 popq**
쿼드워드를 팝하는 건, 스택 탑 위치에서 읽기 작업 후에 스택 포인터를 8 증가시키는 것으로 구현한다. 그러므로 popq %rax는 다음과 같은 인스트럭션과 같다.
```nasm
movq (%rsp),%rax 스택에서 %rax 읽음
addq $8,%rsp 스택 포인터 증가
```
상단의 3번째 열이 pushq 직후 popq %rdx 인스트럭션을 실행한 결과이다. 값 0x123을 메모리에서 읽어서 레지스터 %rdx에 기록한다. 레지스터 %rsp는 다시 0x108로 복구된다.
값0x123은 다른 값이 덮어써질 때까지 메모리주소 0x100에 남아있다.
그러나 스택 탑은 언제나 %rsp가 가리키는 주소를 의미한다. 스택 탑보다 윗부분에 저장된값은 모두 무효인 값이다. 스택이 프로그램 코드와 다른 형태의 프로그램 데이터와 동일한 메모리에 저장되기 때문에 프로그램들은 표준 메모리 주소지정 방법을 사용해서 스택 내 임의의 위치에 접근할 수 있다.
스택 최상위 원소가 쿼드워드이면, movq 8(%rsp), %rdx 인스트럭션은 스택의 2번째 쿼드워드를 레지스터 %rdx에 복사해 준다.
'크래프톤 정글(알고리즘 주차 WEEK 0 ~ 4)' 카테고리의 다른 글
| WEEK 04 여담 TIL(4월8일 화요일) (0) | 2025.04.11 |
|---|---|
| WEEK 04 컴퓨터시스템 (C3-8) (0) | 2025.04.11 |
| 플로이드 와샬 알고리즘 (0) | 2025.04.11 |
| WEEK 04 알고리즘 TIL(4월7일 월요일) (0) | 2025.04.11 |
| WEEK 04 컴퓨터시스템 (C3-1 ~ C3-3) (2) | 2025.04.11 |